Scope Sets as a Piñata for Name Resolution
Recently, I made a couple of tweets on scope sets: (tweet 1, tweet 2)
The key insight behind set of scopes is just… Wow. It’s like a piñata for name lookup.
Instead of thinking in strings/renaming/source ranges/what have you, you approach the problem in a more systematic way and boom, so many nice things fall out.
I wonder if, using this idea, you can make a ✨ name resolution library ✨ (especially for host languages without fancy macros). You create bindings and scopes using certain APIs and you get (multi-threaded? cached?) name resolution “for free”, including in the presence of macros.
That small thread attracted a little bit of interest,
and I figured, “Hey, I actually have a lot more to say
on this than what can fit in a few tweets.”,
hence this short blog post.
Once upon a time (read: 2016), Matthew Flatt wrote a paper introducing scope sets: Binding as Sets of Scopes. The paper describes how you can use scope sets to simplify understanding and implementing name resolution for a programming language with macros, doubly so if said macros are fancy.
I’ve been reading and re-reading the paper on and off, and I really dig it, even though I haven’t fully absorbed all the details. However, I’m not expecting you to have read the paper; I’ll cover the necessary basics as we go.
Here is a rough outline for the rest of this post:
- I discuss macro hygiene and scope sets, and sketch how you can implement name resolution using scope sets. This section is a mixture of a syntax change plus a walkthrough of the initial part of the paper.
- I described why I think that scope sets are a great building block for understanding scope and implementing name resolution. The paper does provide some motivation, but I think there are more good reasons to use scope sets. 😃
- I describe how scope sets can potentially help in implementing name resolution for languages which lack macros but do have other complex scoping-related features.
- I describe what a potential library for name resolution could look like, which could be especially useful for implementing compilers in host languages lacking rich scope-manipulation facilities.
- At the end, I suggest some resources for learning more about scope sets in case you want to dig deeper.
(Disclaimer: This post is not intended as a suggestion to rewrite any existing compilers. This is me thinking out loud about how new compilers could be implemented.)
Let’s start with the basics.
Basics of Scope Sets
Say you have some ML-like language with top-level let definitions,
let in expressions and macros. Here’s some pseudocode:
let x = 1
macro get_x = x (* x is the value defined earlier *)
let y =
let x = x + 1 in
get_x (* y = 1 *)If we try to expand this code naively, we get:
(1) let x = 1
(2) macro get_x = x (* x is the value defined earlier *)
(3) let y =
(4) let x = x + 1 in
(5) x (* y = 2 *)If we try to resolve the x introduced by expanding the macro,
the reference to x on line 5
will be bound to the binding for x on line 4.
We just changed the meaning of the program! 💩
The problem here is one of hygiene. Naive substitution is not hygienic. In this case, we accidentally captured an identifier based on what was in scope at the site of expansion. One can also have the opposite issue: accidentally shadowing an identifier based on what is in scope at the site of expansion.
You might be wondering “oh, why don’t we rename the variables
in the compiler to say x1 and x2,
that would help us disambiguate.”
And that would be correct, you can implement a hygienic macro system
using renaming.
However, using renaming to implement hygiene is not great for a few reasons:
- It can get slow as you need lots of tree traversals to rename variables.
- Depending on how it is implemented, it is easy to get wrong.
- Presenting renamed identifiers in diagnostics is arguably bad UX.
- It doesn’t scale to more complex macro transformations.
- It has poor aesthetics.
Turns out, many smart people have given a lot of thought to this problem over the years. This post is not about that; you can check the bibliography in Flatt’s paper if you’re interested. What this post is about, is one really cool innovation in this space: scope sets. Here is the core idea:
- Binding forms
– such as (value/macro) definitions,
letexpressions and lambdas – and macro expansions introduce fresh scopes. - Due to nesting, pieces of syntax – such as references and bindings – have a set of scopes.
- When trying to resolve a reference, the best binding is the one whose scope set is the biggest subset of the scope set for the reference.
It’s best to illustrate this in action with an example; let’s reuse the one from earlier:
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} + 1 in
(5) get_x{a,b,c}The letters a…c are made-up names for scopes, and a {...} indicates
a scope set. How did I go about assigning the scopes?
Rule 1A: A non-recursive binding form introduces a fresh scope that applies to the binding and all pieces of syntax present after the end of the definition.
Here’s how Rule 1A applies here:
ais a fresh scope introduced by the definition forxon line 1; notice thatx’s scope set as well as every scope set later has anain it.bis a fresh scope introduced by macro definition forget_x; notice thatget_x’s scope set as well as every scope set later has abin it. Thexreference on line 2 is part ofget_x’s definition, it’s not after the end, so its scope set doesn’t haveb.cis a fresh scope introduced by thelet x = <..> in <..>; notice that the bindingxhasc, and so does the macro invocation, but thexreference on line 4 doesn’t havecin its scope set. (“End of definition” for alet inexpression should be interpreted as being right before the start of its body for this to work.)
Now that we understand the structure, let’s look at resolving names.
Rule 2: A reference resolves to a binding if:
- The binding has the same identifier as the reference.
- The binding’s scope set is a subset of the reference’s scope set.
- Out of all bindings satisfying 1 and 2, it has the biggest scope set.
(Given a set
A, and a set of its subsets{Ai | i ∈ I}, a particular subsetAjis the biggest subset if for every choice ofi ∈ I,Aiis a subset ofAj.)
Let’s try to apply Rule 2 for resolving the references to x.
(I’ve duplicated the code example from earlier for convenience.)
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} + 1 in
(5) get_x{a,b,c}There are two candidate bindings for x, one on line 1 with scope set {a},
and another on line 4 with scope set {a,b,c}. Applying Rule 2:
- The x reference on line 2 has scope set {a}: out of
{a} and {a,b,c}, only {a} is a subset of {a}.
So the x reference on line 2 is bound to the x on line 1.
- The x reference on line 4 has scope set {a,b}: out of
{a} and {a,b,c}, only {a} is a subset of {a,b}.
So the x reference on line 4 is bound to the x on line 1.
So far, so good. Let’s expand the macro and see if it still works.
(1) let x{a} = 1
(2) macro get_x{a,b} = x{a}
(3) let y{a,b} =
(4) let x{a,b,c} = x{a,b} in
(5) x{a,d}Rule 1B: Expanding a macro introduces a fresh scope which is applied to all pieces of syntax in the macro’s body.
Using Rule 1B, a fresh scope d is introduced by the macro expansion,
and this gets added to the scope set {a} for the x reference in its body,
resulting in x{a,d}.
If we try resolving the reference x on line 5, the binding for
x on line 4 is ignored as {a,b,c} is not a subset of {a,d}.
So the reference will correctly be resolved to the binding x{a} on line 1.
Yay, we didn’t mess up scope! 🥳
I’m going to skip discussing more complicated situations – such as recursive bindings and recursive macros – since they aren’t necessary for the rest of this post! Check out the paper for the nitty-gritties. For now, you can take my word that it works out.
Having talked about the happy case, let’s run through the error cases:
- In case there is no binding, that’s an “unbound identifier” error.Yes, this is partly a nod and partly an eye-roll at the OCaml compiler.
Last time I remember using it,
it used to have messages exactly like this one “unbound identifier X”.
Please don’t write diagnostic messages using compiler-specific jargon
unless absolutely necessary. Thank you for coming to my TED talk.
- In case there is no best binding – for example, you could have two candidate bindings but their scope sets have a non-empty symmetric difference – that’s an ambiguity error.
Stepping back a bit, let’s crystallize our understanding:
- A piece of syntax is a pair consisting of an identifier and a scope set.
- Resolving a reference involves trying to find the binding whose scope set best matches the reference’s scope set.
- A scope set
Sis the best match for another scope setTif for every scope setUthat is a subset ofT,Uis a subset ofS. - No identifier is bound multiply with the same scope set.
The last restriction is not something we’ve discussed; but it’s not unreasonable, especially in the context of an ML-like language.
If you want to handle type-based overload selection in the style of Java, C++ and so on, that could be modeled by initially resolving names up to an overload set. That is, different overloads in the same overload set get smooshed together by the name resolver into the same equivalence class. The type-checker can handle selecting the right overload later on. (That said, I’m not entirely sure if this would work for C++ given that its overload resolution rules are kinda’ hairy.)
Why scope sets rock
Okay, maybe by this point, you think scope sets are cool.
Or maybe you’re underwhelmed.
If you’re underwhelmed, let me walk you through the
reasons for why I think scope sets rock.To comply with the SEC’s disclosure requirements,
I would like to disclose that I am 66% emotionally invested
in scope sets being used as an implementation technique in
future industrial-strength compilers.
Clear recipe for modeling common rules
Two of the most common behaviors associated with scoping are shadowing and ambiguity. The scope sets approach provides a clear recipe for how to make sure one binding shadows another – its scope set needs to be a superset of the other’s scope set – and how to create ambiguity – the scope sets should overlap without either one being strictly bigger.
Let’s consider ambiguity first. In many languages, it is common for imports to be order-independent, so that one can rearrange imports without worrying that the code will stop compiling. The usual behavior in this situation is that if identically named bindings are available through multiple distinct imported modules, the compiler issues an ambiguity error when one attempts to use that binding. For example, here’s what it looks like in Swift:
import A1 // exports a
import A2 // exports a
let x = a // error: ambiguous reference to 'a'According to scope sets, to get this behavior, the imports for A1
and A2 should have scope sets in a way that
neither of which is a subset of the other.
That’s easy enough: we could mark the exported bindings in A1 and A2
with different scopes, say SA1 and SA2
and have the code in the current module start out with the scope set
{SA1, SA2}.
Resolving the reference to a would fail; the reference would have
scope sets {SA1, SA2} whereas the candidate bindings would
have scope sets {SA1} and {SA2}, neither of which
is the best candidate.
Moving on from ambiguity to shadowing; that too has a natural solution – introduce an intermediate scope set. Again, taking an example from Swift, Swift has a facility to mark if an import from one module should be preferred over another for unqualified lookup:
import A1 // exports a
import A2 // exports a
import var A2.a // A2's a should be preferred
let x = a // OK: a refers to A2.aOne can model import var as if it adds an intermediate scope.
In this case, say import var A2.a introduces an intermediate scope SA2.a
between the usual imports and the code in the module.
This would mean that:
anow has 3 bindings, with scope sets.{SA1},{SA2}and{SA1, SA2, SA2.a}.- The reference to
awill have scope set{SA1, SA2, SA2.a}.
This will make the scoping work as expected.1
Decoupling “is” from “how”
One really nice thing about scope sets is that the whole idea decouples what a scope is from how a scope is created in a program.
A scope is some abstract region in the program.
How did it manifest?
Maybe the compiler inserted a scope because
the programmer wrote something (such as { ... })
or there was a macro expansion
(or the compiler itself implicitly added some code).
Maybe it corresponds to some specific nodes in the AST, maybe it doesn’t.
Maybe it corresponds to a set of source ranges, maybe it doesn’t.
Maybe some identifiers got renamed.
Maybe it’s Maybelline.
This separation of scope creation and name resolution means that from the perspective of name resolution, it doesn’t really matter how the scopes came about. So long as name resolution ends up with the same scope structure, it will resolve things the same way.
If you’re designing a new language feature, you can ask two distinct questions: “does this change how scopes are created” and “does this affect how names are resolved”.
Visual affordances
One common headache with understanding scoping in complex situations, is that you constantly need to play compiler in your head. But the compiler already exists?! 😂 So why should the programmer role-play as the compiler? Why can’t the compiler show the programmer why it picked a particular binding (or why something is ambiguous)?
Part of the issue is, with an ad-hoc implementation of name resolution, it is not really clear how to present this information in a way that is understandable without being overwhelming. Should the compiler provide some kind of log: “I looked here, that failed, so I looked there, that failed, so I finally looked over there and found what you wanted.” Maybe that’s tolerable for a compiler engineer, but can that be displayed in an IDE in a helpful way?
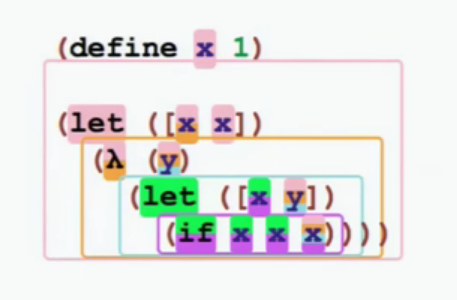
With sets of scopes, there are some nice visualization opportunities. For example, I showed superscripts before. An IDE could make those superscripts clickable and show where the scopes are coming from. In Flatt’s talks, he uses a representation of scopes using colors (shown below).
- Each scope has a unique color.
- References and bindings are enclosed in bubbles with one or more colors, indicating scope sets.
Sets have nice algebraic properties
At the risk of over-simplifying, the reason why scope sets work well is two-fold:
- They allow direct manipulation of scope, instead of it being modeled implicitly.
- There is a nice algebraic structure to the subset relation: a partial order.You can also reframe this point in terms of the semilattice formed
by the union operation, but I found it more useful to formulate it
in terms of a partial order as the previous discussion is in terms
of subsets.
Recall that a partial order on a set A is a binary relation ≤ that is
reflexive (a ≤ a), antisymmetric (a ≤ b and b ≤ a implies a = b)
and transitive (a ≤ b and b ≤ c implies a ≤ c).
(In case you’re unfamiliar with the terminology,
check out Matt Might’s post
Order theory for computer scientists.)
How are the properties of partial orders related to how we think about scope?
- If one binding is closer to a reference than another binding, which is closer to the reference than yet another binding, then the first binding is the closest one out of the three: this is transitivity in action.
- Our restriction of “No identifier is bound multiply with the same scope set”
is antisymmetry in action.
(If we remove antisymmetry, we’d get a preorder. A preorder has a natural
mapping to a partial order by creating equivalence classes based
on
a ≤ bandb ≤ a, which mirrors my point about overload sets.) - If you have a set of elements
{ai | i ∈ I}taken from a partial order, it may be the case that there does not exist any elementaj, j ∈ Iwhich is greater than or equal to all the other elementsai, i ∈ I.- If the set is empty, the “exists” part fails: this is the unbound reference error.
- If the “all” part fails: this is the ambiguity error.
In some sense, I’d argue that partial orders are perfect for thinking about scope.
If you’re not used to thinking about algebraic structures in your code, you might be wondering: why is this useful? Like, OK, there’s some algebra, cool. But aren’t we essentially saying the same thing, but in a different way? Well… no! Thinking algebraically has several benefits:
- We’ve separated out the essential from the accidental, so it’s clearer what role different parts of a design are playing.
- It gives us an opportunity to abstract over the algebraic structure of interest, so that we can modularize our code into a library.
- It provides useful design pressure; if you’re coming up with some scoping rules and those can’t be modeled using a partial order, maybe you should step back and consider if the thing you’re introducing has some edge cases that you didn’t think of, and maybe people might find them unintuitive.
- Algebraic structures compose well. For example, a pair of partial orders can be composed to create a new partial order.2
This gives us some food for thought: are there other language features that are scope-like or have a partial order structure? Can we combine them with scope? Let’s find out! 😉
Scope Sets for implementing languages lacking macros
As I mentioned earlier, in Binding as Sets of Scopes, Flatt points out how scope sets can be helpful for implementing languages with (expressive) macro systems. I think the idea can be extended further and that we can use scope sets (or extensions of it) to simplify implementing name resolution for languages which lack macros, but do have other kinds of complex features, such as:
- Native support for writing target-specific code.
- Native support for conditional compilation.
- Renaming imports.
- OO-style scoping rules.
I also discuss how scope sets can potentially help develop tooling.
Modeling target-specificity
If you write software day-to-day, chances are, you’ve written code that is only intended to be used on specific targets. Maybe you’ve written code that only works on:
- A particular browser or browser version.
- A particular OS or OS version.
- A particular architecture, architecture version or subarchitecture.
Depending on the code, there may be a fallback implementation for other targets, for portability. Or there may not be any fallback because the code is deliberately target-specific.
Maybe the target check needs to happen dynamically; for example, you may want to provide one binary that runs on multiple OSes, and it needs to have some workarounds for older OS versions. Or maybe the code is built with the exact target known up front.
Depending on the language, these might all be modeled in distinct ways. For example, in Swift:
- The
@availableattribute that can be used to mark declarations as available only for specific OS versions (for Darwin-based OSes). #availablecan be used to do a target check at run time.#if os(...),#if arch(...)and similar can be used to do conditional compilation.
In short, handling target-specificity can be a complex affair for both compilers and programmers. Can we simplify it? I think so!
The notion of target-specificity is, in some sense, exactly the dual of scoping! Scoping is about “where is this fragment of the program defined”, target-specificity is about “where can this fragment of the program be used”.
To be more precise, target-specificity can be modeled as a partial order under the superset relation (an element of the set is a target which is supported):
- Code that works on all targets is the least specific.
- Code that works only on (say) arm64 is more specific than 1.
- Code that works only on (say) macOS is more specific than 1 but neither more nor less specific than 2.
- Code that works only on (say) arm64 macOS is more specific than 2 and 3.
Here’s the kicker: remember my point about partial orders being composable? We can combine the two concepts – scope sets and target-specificity – into a single concept: a domain. (Better name suggestions?) If we replace all uses of “scope set” with “domain”, and make some minor wording changes, everything just works.
- A piece of syntax is a pair consisting of an identifier and a domain.
- Resolving a reference involves trying to find the binding whose domain best matches the reference’s domain.
- A domain is applicable to another domain if:
- Its scope set is a subset of the other domain’s scope set.
- Its target-specificity is less specific than the other domain’s target-specificity.
- A domain
Dis the best match for another domainEif for every domainFthat is applicable toE,Fis a applicable toD. - No identifier is bound multiply with the same domain.
With these points in mind, let’s revisit the target-specificity example I gave earlier in the context of a hypothetical Swift-like language:
let x = 0 // Cross-platform by default
@target(arch: arm64)
let x = 1
@target(os: macOS)
let x = 2
@target(arch: arm64, os: macOS)
let x = 3
// No errors for multiple 'x' bindings in same scope as they have
// different target specificities (and hence different domains).
let y = x
// Say we are compiling for multiple platforms.
// The reference to 'x' will pick up the most specialized value.
// x86_64 Linux: y == 0
// arm64 Linux: y == 1
// x86_64 macOS: y == 2
// arm64 macOS: y == 3While the example is contrived, I hope it illustrates the point of how this would work in practice.3
Why is bundling together target-specificity with scopes useful? I think doing so can make it easier to correctly implement simultaneously type-checking code for multiple targets (when the conditional compilation flags for each target are the same; more on conditional compilation in the next section).
That said, before describing how type-checking would change, it’s worth talking about how target-specificity works today in modern compilers.
For languages that support target-specificity,
compilers today go through the entire compilation pipeline
for every target that you’re compiling for.I’d be happy to be proven wrong if you know of a counter-example!
For example, if you’re creating a
universal binary
for a macOS application that will run
on Intel-based Macs and Apple Silicon-based Macs,
then Xcode will invoke the compiler (Clang or Swiftc) twice,
one for each target, and then combine the resulting binaries together.
This means that the code will be type-checked twice,
even if none of the code that you wrote is target-specific! 😔
I think the reason behind this behavior is (as always?) history.
- C doesn’t have any native support for API versioning.
- Userspace code has to go through syscalls (provided as C APIs), or libc (also C).
- Different OSes and libc implementations have their own versioning schemes.
- Due to 1, and the nature of the C preprocessor, C compilers compile for targets one at a time.
- Due to 2, 3 and 4, other compilers have copied this aspect of C compilers’ design and compile for targets one at a time.
To be fair, some modern languages do improve on this to an extent.
Recall Swift’s @available attribute that I mentioned earlier
which handles OS versions.
Even though there is no macOS 9000,
the following code reports a type error.
@available(macOS 9000, *)
public let x: () = 0 // error: cannot convert value of type 'Int' to specified type '()'But that’s only for OS versions; target architecture checks go
through the general conditional compilation construct #if,
which means the following compiles on x86_64:
#if arch(arm64)
let x: () = 0
#endifHowever, this state of affairs doesn’t need to continue for future languages. If identifiers keep track of the full target-specificity, we’d have the following benefits:
- We can share most of the type-checking work across targets when the code being compiled is largely cross-platform. 4
- Earlier detection of non-portable code: If you are working on a cross-platform project on (say) Linux, but you end up calling a function that is not available on Windows, you’ll get an immediate error saying that name resolution failed to find a cross-platform definition, instead of having to wait for a compilation error on the Windows CI.5
- Better diagnostics in the presence of cross-platform differences: Since all definitions are considered – instead of some definitions being ignored as with conditional compilation – a compiler can suggest better matches when there are errors in writing target-specific code.
Modeling conditional compilation
In the previous section, I discussed how one could potentially combine target-specificity with scope sets to handle type-checking for multiple targets simultaneously.
Recall that I also mentioned how Swift models target-specificity partly through conditional compilation. From what I understand, this is also true in Rust; target-specificity is very much based on conditional compilation.
However, the state of conditional compilation in today’s languages isn’t all that great:
- In languages using preprocessor-based conditional compilation (C, Haskell etc.), code that is conditionally compiled out doesn’t even need to parse correctly.
- In more modern languages like Swift and Rust, code that is conditionally compiled out needs to parse correctly. This makes writing language tooling easier. However, it is not type-checked.
Type-checking code that is going to be conditionally compiled out is a natural extension of the “needs to parse correctly” requirement; detecting errors sooner is arguably preferable than detecting them later. This is increasingly true as the number of configuration options explodes combinatorially with large projects; is your code even going to compile if someone flips some options?
Say you’re working on testing and deploying something under a compile-time feature flag. You enable the flag in a tiny commit and kick off some complex testing. A colleague comes and makes a change. Your testing discovers some issues, so you try reverting your change. Surprise, surprise, the code no longer compiles! 💩
There are a couple of alternatives which don’t suffer from this failure mode: (1) you setup some CI bot to make sure both configuration continue to compile, or (2) you use a run-time feature flag instead of a compile-time feature flag. However, neither of those is a perfect substitute for a compile-time feature flag; the run-time feature flag likely doesn’t work if a type needs to change based on the flag, and creating CI bots for every permutation of feature flags does not scale.
That begs the question: is there a fundamental reason stopping us from “seeing through” conditional compilation? We probably don’t want to do codegen for all permutations of feature flags, because we’re not going to run all permutations, but why can’t we get semantic analysis for all permutations?
Taking a cue from the previous section, maybe we should rephrase the question: can we model conditional compilation similar to how we modeled target-specificity? More precisely, is there an intuitive partial order on conditional compilation expressions that we can use?
For simplicity, let’s consider a grammar for conditional compilation expressions using only boolean expressions, and the ability to use boolean-valued feature flags:
ccexpr := true
| false
| feature-flag
| not(ccexpr)
| and(ccexpr+)
| or(ccexpr+)Is there a nice partial order on such expressions? Turns out, there is!
Satisfiability!
If you have two expressions c1 and c2 then c1 ≤ c2
(read: c1 is less specific than c2)
if for every substitution of feature flags, it is the case that
if c2 is true then c1 is true (that is, c2 implies c1).
The proof that satisfiability with ≤ as defined above
forms a partial order is left as an exercise to the reader. 😛
(Hint: Use conjunctive normal form for antisymmetry.)
That said, let’s at least do a quick spot check
to make sure we got the polarity right:
and(flag1, flag2) implies flag1, which would mean that flag1 is
less specific than and(flag1, flag2). Cool.
Now, I’m not saying that a compiler should casually call a SAT solver routine
in the middle of name resolution.I have a lurking suspicion that given that most application-level code
is written to be cross-platform to a degree, and people generally don’t
use compile-time feature flags in wild ways, one might be able to make
this work with good performance by special-casing fast paths and
judicious caching.
It probably should not.
However, given the cute outcome of having a partial order
on conditional compilation expressions,
let’s pretend for a bit that domains are now a triple
consisting of a scope set, a target-specificity
and a conditional compilation expression.
What benefits does this have in practice? The list is similar to that for target-specificity:
- If a package is being compiled multiple times with different sets of feature flags, most of the type-checking work – which is not behind a feature flag – only needs to be done once.
- Earlier detection of semantic errors in code that is conditionally being compiled out under the current build settings.
- Better diagnostics in case there is a feature flag mismatch: If you accidentally try using an API that is only available under a feature flag, a compiler can provide a more useful diagnostic if it understands that the API is feature-gated.
Renaming imports
Facilities for renaming things in import lists are quite prevalent; out of the languages I’m familiar with, Rust, Python and Haskell all support renaming things on import to varying extents.
As an example, Swift supports a feature called “cross-import overlays”. It is best illustrated with a code example:
import SwiftUI
import MapKit
// Compiler looks at both imports (+ some files in the SDK) and
// implicitly inserts 'import _MapKit_SwiftUI', which is marked
// as a cross-import overlay for the (MapKit, SwiftUI) pair in
// the SDK.
import _MapKit_SwiftUI // (compiler-synthesized) exports MapView
typealias MV1 = MapView // OK, MapView comes from _MapKit_SwiftUI
typealias MV2 = MapKit.MapView
// OK, MapKit is marked as the "declarating module" for _MapKit_SwiftUI,
// so this behaves as if the user wrote _MapKit_SwiftUI.MapViewSimilarly, for diagnostics and documentation,
MapView behaves as if it was defined in MapKit,
even though it is defined in the module _MapKit_SwiftUI.
One can model the name change using scope sets;
if an imported module is a cross-import overlay (here, _MapKit_SwiftUI),
it reuses the scope for its declaring module (here, MapKit),
instead of creating a fresh scope.I’m glossing over some additional complexity here due to how
Swift’s @_exported import interacts with shadowing.
(Cross-import overlays are expected to use @_exported import
for the declaration module and the bystanding module.)
As this example goes to show, renaming is in some sense a matter of scope adjustment, which scope sets are good at modeling.
OO-style scoping rules
Object-oriented features in languages often come with their own scoping behavior, where proximity is not only lexical, but type-based as well.
For example, resolving fields/properties and methods needs to go look through superclasses. Traits and protocols are somewhat similar to superclasses from a name resolution perspective; instead of going looking through a sequence or DAG of superclasses, one has to look through a forest of traits/protocols. Many languages also support “extension methods”, where you can add methods to a type that was already defined earlier.
I think that the scoping behavior for these constructs should be
implementable by adding intermediate scopes based on types.
For example, if a class Animal has a declaration scope SAnimal,
that scope should be added to the scope sets
for everything defined in a class Cat which subclasses Animal,
so that method lookup finds things
in the superclass as well. However, depending on the complexity
of the system, name resolution may need to be partly or completely
intertwined with type-checking.
Tooling support
As languages grow, people have greater expectations from the tooling ecosystem around the language. For example, with documentation comments, it is valuable to be cross-reference definitions for faster navigation.
One way in which scope sets could be useful here is that they provide a nice abstraction for a documentation compiler (something that extracts documentation from source code, resolves cross-references and emits output in say HTML format or similar) to work with.
For example, say you are writing the documentation for a public function
in a file. However, in the documentation you refer to a function that was
forgotten to be marked as public.
While calling a private function in a public function’s implementation
should be okay,To be pedantic, this should almost certainly be an error
if you have a language which has a stable ABI
and the public function’s implementation is exposed…
referring to a private function in a public function’s documentation
is almost certainly a mistake.
So this is one example where we’d like the scoping rules for documentation
to be somewhat different than for code in that particular file.
If we try implementing the documentation compiler
using a naive approach (splicing files, munging with imports etc.),
it is more likely that we get such details wrong.
We also likely don’t want to implement name resolution a second time;
once in the usual compiler a Frankenstein version of it
in the documentation compiler.
For this particular case, one potential fix would be to have an additional
Sprivate scope:
- This scope is added to all private declarations.
- This scope is added to all implementations (for both private and public declarations).
- This scope is added to all references in doc comments for private declarations.
Since this scope will be missing from references in doc comments for public declarations, one will get an scoping error on trying to refer to a private function.
Coincidentally, this fix also models the restriction that a public declaration cannot refer to a private declaration (for example, a public function cannot refer to a private type).
Name resolution as a library
If a compiler’s host language has sophisticated macros,
it is possible for the compiler to piggy-back off the host language’s macro system
to implement scoping for the target language;
I believe Hackett does this.I haven’t checked though, so don’t take my word for it.
There has also been some recent work on how to make this work
for DSLs: see Macros for Domain-Specific Languages.Thanks to Sam Elliott
for bringing this paper to my attention!
However, most compilers are written in host languages which do not have macro systems as flexible as Racket’s. So I think it would be useful if name resolution could be made into a library to make writing new compilers easier in host languages without macros.
Given that using scope sets separates out how scopes are created from how name resolution works, I believe it should be possible to implement a library for name resolution that is sufficiently flexible to account for a variety of target languages.
More concretely, here is what the core API for such a library could look like:
- An scope type.
- API: This is an opaque handle and doesn’t provide any functionality apart from checking equality and hashing.
- A scope set type.
- API: General set functionality like adding scopes, removing scopes, querying for membership and checking if one scope set is a subset of another scope set.
- A scope generator.
- API: Create a fresh scope distinct from any other scope.
- A name resolver type.
- Type parameters:
- A type for identifiers.
- A type for bindings (or more generally, any per-binding metadata).
- A domain type describing the partial order to be used for name resolution. By default, most clients would use domain = scope set.
- API:
- Adding a new domain and binding information for an identifier.
- Resolving an identifier in a particular domain. This would return either the corresponding binding or an error (not found or ambiguous).
- Type parameters:
Here’s how using such a library would look like:
- Client creates new scopes and scope sets according to the target language’s scoping rules and attaches them to different contexts in its own code.
- Client updates name resolver whenever it creates a new binding.
- Client queries name resolver whenever it tries to resolve a reference.
The library can implement caching for resolution queries based on the identifier and a monotonic modification time for the list of domains for that identifier.
Depending on the choice of data structures, it might even be possible to have this library support safe multi-threading, so that multiple threads can talk to the same name resolver. Doing so could help reduce memory usage as much of the scope information across threads is likely to be shared. This could also help reduce duplicate work done across different threads.
For simplicity, I’ve only described the core API here. In practice, the API would likely need to be more complex for better efficiency.6 There’s probably some other details I’m missing as well, but I hope you get the general idea. I’m not entirely sure if this would work, but I’m optimistic.
Closing thoughts
If you’ve made it so far, chances are, you’re convinced that you should least consider learning more about scope sets before you start implementing your next compiler.
So where should you start learning more?
Flatt has an accessible RacketCon talk describing how scope sets work, and how they improve on prior models of macro expansion. Flatt also has a Strange Loop 2016 talk, which has some overlap with the former, but is focused more on the implementation side of things – he walks through how you can build a hygienic macro expander using scope sets. Then there’s always the original paper itself: Binding as Sets of Scopes.
In case you don’t have a strong preference for one medium over another, I suggest checking out the resources in the following order: RacketCon talk → StrangeLoop talk → paper. (The HTML version of the paper has nice syntax highlighting and cross-linking.) I recommend watching the RacketCon talk before the Strange Loop one even if you’re not familiar with Racket; I think the latter is a bit of a whirlwind (it’s very good, but it takes some time to absorb), whereas I found the pacing for the former to be closer to my preferred sweet spot.
On the implementation side of things, as far as I know, at least 3 compilers are using scope sets today: Klister, Racket and Rust (in order of increasing compiler size).
If you want to study Klister’s implementation, here are a couple of good entry points: scope sets in Klister and resolution in Klister. There is also some short commentary on the implementation.
If you want to take a look at Racket’s implementation, you may want to start from the definition of the core resolve function.
I haven’t looked at Rust’s implementation, although I do recall hearing that the new “macros 2.0” feature is implemented using scope sets. Nick Cameron has written several blog posts on macros and hygiene in Rust. For example, you may want to check his blog post on scope sets.
Last but not the least, I cannot recommend the Racket documentation highly enough. For the particular topic of scoping specifically check out: - The Racket guide’s discussion on phase levels. - The Racket reference’s description of Racket’s syntax model.
Maybe you’re thinking: isn’t this essentially doing the same thing as desugaring the code to have an additional
private let a = A2.aand putting the module’s code into an additional scope? Well, it depends. Depending on the language, not all scopes work sufficiently uniformly; the top-level scope is special. For example, in Swift, a naive desugaring wouldn’t work depending on the access control levels.import A1 import A2 private let a = A2.a do { public let x = a // error: attribute 'public' can only be used in a non-local scope }Additionally, even if this could be made to work, desugaring needs more work to maintain the same quality of diagnostics. (Not to say that one shouldn’t work on improving diagnostics for desugared code; check out Justin Pombrio and Shriram Krishnamurthi’s work on resugaring.)
I’d argue that modeling the import behavior as scope manipulation is a clearer description of what is going on: one is not generating code, one is only changing what is and is not in scope.↩︎
There are 3 ways to define a partial order on a pair of partial orders P and Q while using both of them: 1. Compare using P first; breaking a tie by comparing using Q. 2. Compare using Q first, breaking a tie by comparing using P. 3. Compare using both P and Q, if they are consistent, then use the result, otherwise report an ambiguity.
On the Swift bug tracker, one of the frequently reported bugs that gets marked as “works as intended” is a manifestation of people expecting one partial order to be used for name resolution (in the presence of overloads) whereas the actual implementation uses a different one.
Hand-waving things a bit, there are two partial orders when doing name resolution in a language with overloads such as Swift: the one for scopes and the one for overload specificity.
Swift picks strategy 1, it prefers (lexically) closest overloads first. If there are multiple, it will do overload resolution amongst those and ignore overloads which are further out (but may be more specific).
People who file that bug expect strategy 2, where they’re like, “Why didn’t the compiler pick the further out overload since it’s clearly more specific than this closer overload?”
It’s not an unreasonable point, but also… I feel that, this is one of those things where the fundamental nature of the problem (there are 3 possible strategies, not a unique one) means that someone will find the behavior unintuitive regardless of what is chosen.
Speaking for myself, my personal preference for combining partial orders for name resolution (if I were implementing a new language) is strategy 3. However, that also has issues: (i) it would make strictly less code type-check and (ii) it would be slower than either strategy 1 or 2, because you always have to do 2 comparisons.↩︎
I’m making a bunch of simplifications here for the sake of exposition. First, there is no monolithic “Linux version”. Sure, there are different versions of different distributions, and there are different versions of the kernel, but exposing the complexity of all that to every programmer is likely to be too much. So it’s not clear how this would work for all targets.
Then comes the question of evolution. Say the compiler adds support for RISC-V as a target architecture. Does existing code automatically start being checked for “does this work on RISC-V”? Is there some kind of checkpoint system with editions, where new platforms are only added to a default set with new editions?
There’s also the question of being able to force-override things using (say) a compiler setting or a build system setting. Continuing the example from before, if RISC-V support is being added, it would be useful to see how much code will not work for RISC-V, without having to make invasive changes to the library’s source code.↩︎
I’m getting a bit carried away here; being able to do name resolution it not the same as being able to do type-checking. Specifically, if one allows type equality to be target dependent, such as by allowing a typealias to point to different types for different targets, checking type equality requires some additional work. Here’s an example, continuing with fake Swift-like syntax from earlier:
↩︎typealias MyInt = @target(pointer_width: 32) Int32 @target(pointer_width: 64) Int64 typealias YourInt = @target(pointer_width: 32) Int32 @target(pointer_width: 64) Int64 @target(pointer_width: 32) let x: Int32 = MyInt(0) // OK @target(pointer_width: 64) let y: Int64 = MyInt(0) // OK let z: YourInt = MyInt(0) // OK let w: Int32 = MyInt(0) // error: MyInt is Int32 only for 32-bit targetsThis is better than cross-compilation (when limiting the discussion to semantic analysis) for two reasons:
Using cross-compilation would still require code to be type-checked twice (with modern compilers), even though most code is likely to not be target-specific.
Creating a great cross-compilation toolchain experience is hard. I’m not saying it’s not worth doing, it absolutely is. However, if someone only wants semantic checking and is not actually looking to run code because they don’t have any devices for the particular target then asking them to setup a full cross-compilation toolchain is a big ask (unless you make it ridiculously easy).
That said, Zig is doing some cool work in this space, so maybe the future is better than whatever nonsense people need to put with today. 😃
For efficiency, we probably want to have a slightly more general API.
- A domain type has an associated “region” type, which is an indivisible unit of a domain. The region for a scope set is a scope.
- The name resolver provides an API to mark a region as “dropped”. Dropped regions behave as if all domains containing that region are ignored for name resolution. This lets us free memory used by different lookup structures, such as an identifier lookup table and the individual domain lists.
- A library client updates the name resolver whenever it is done running name lookup in a scope (or more generally, a region).
One might also want to have some interning for scope sets (or generally domains and/or domain lists), to reduce memory usage.↩︎