Experience Report: 6 months of Go
I’ve been working at Sourcegraph for about 6 months now. During that time, I’ve mostly been writing Go, in the context of server-side development. I also gave a lightning talk on reading the Go spec at GopherCon.
During this time, I’ve been making notes of speed bumps I’ve run into, as well as things I’ve liked about Go. This post is an expanded version of those notes. I’ve tried my best to keep away from abstract examples, and focus on actual things I’ve run into myself.
For context, I’ve previously written C++ for ~2.5 years in a professional capacity. Other languages I’ve written a fair bit of code in (recent first) include TypeScript, Rust, Haskell, Swift, OCaml, Python and Mathematica. My personal preference skews towards ML-like languages. I also prefer APIs that try to make data valid-by-construction, and make illegal states unrepresentable. That said, I understand that not everyone cares about these to the extent that I do (some care more, many care less, and that’s OK).
Disclaimers
Negativity bias
I’m not free from negativity bias. It’s much easier to identify what is wrong rather than what is right. That’s part of the reason why this post has many more negative points rather than positive points. The other reason is that I’m coming in to Go with a set of baseline expectations from other (largely statically-typed) languages. I’ve tried my best to come in with an open mind.
A holistic view
Certain internet commenters share the belief that one should separate out discussions of the language itself from related stuff like the standard library, tooling etc. IMO, that is not terribly useful in most cases. The end-to-end experience is what matters. A programming language is not merely an abstract entity to be studied under a microscope but rather a tool to be used and exercised in context. This post deliberately juxtaposes my experience with the language, tooling, package ecosystem and community.
Why even write this
- I use Go at work and I’m hoping that this post can spark a conversation around language and compiler improvements.
- If you’re developing a new programming language, I’m hoping you read this and come away with a better understanding on what you should and should not copy from Go.
This isn’t written for catharsis. If anything, I’ve become more depressed in the process of writing this post.
Okay, enough explanation and disclaimers.Can you tell I’m reading Twitter, Reddit and Hacker News too much?
Let’s go.
Positives
Speedy compile times
I knew that Go had a reputation for fast compilation, so I wasn’t too surprised by this, but it’s hard to overstate the productivity impact of fast compile times. At work, we have a nice automatic reloading system which recompiles the relevant binaries, kills the service processes, and spins up new ones. This speeds up iteration quite a bit. The best part is that it doesn’t really matter how deep in the dependency tree I change something. The other day, I changed one of the core logging functions, which forced recompilation of nearly all binaries. And yet, everything was recompiled and reloaded within 10 seconds.
And that’s not where it ends; it looks like there is ongoing experimental work on an even faster toolchain for Go.
With C++, incremental compilation can be fast if you’re only changing a C++ file, but linking on macOS with ld64 is relatively slow, and changing code in headers throws a wrench into the gears.
Changing pervasively used structures in C++ or Rust can cause recompilation that takes over a minute. That is enough time to get distracted by something else, like Slack.
Good built-in profiling support
Go comes with built-in sampling profiler called pprof
(not to be confused with the Linux profiling tool perf).
Using it, you can investigate CPU usage, memory usage
(these are the main two bits I’ve used) as well as
mutex contention, goroutines etc.
After a profile is recorded, you can visualize the output as a call graph with weighted edges or a flamegraph (for the CPU profile) or in other formats. This provides a good out-of-the-box experience.
Is it the most sophisticated profiling tool? No, it isn’t. However, it’s a good tool for rough investigations where you’re trying to get a high level picture of where your application is spending time.
Default optimization mode strikes a good balance between debuggability and performance
Using a debugger with a Go binary largely works well. For example, examining local variables works more often than not, which does not necessarily hold for C++ code built with optimizations.
This is one of the positives examples of design decisions acting as a forcing function to make things better. My understanding is that Go deliberately eschews configurability (e.g. a C++ compiler usually has tons of flags to control optimizations) in favor of a “just works” solution. Having this design constraint means that balancing debuggability while maintain performance is important.
This is something that I think many compilers get wrong,
including Rust, where the default mode (debug) has
a very large performance gap from release.My untested guess is that other languages could do
a better job here by at least running a basic register
allocator that: (1) actually uses registers instead of
spilling everything to the stack
(watchpoints are arguably less useful in memory-safe languages,
so it’s probably an OK default)
and (2) Is less aggressive about shrinking live
ranges and reusing registers compared to the
one used for release builds.
I’m too lazy to check if LLVM has such a register allocator
that works out-of-the-box, but if it does,
it probably makes sense to use that as the default.
If it doesn’t, maybe someone should write such
a register allocator and upstream it.
(If you do this, I will buy you one (1) dinner, as a treat.)
Swift gets this right to an extent with mandatory inlining, but I feel like Go probably strikes the best balance of all the languages I’ve tried.
Of course, Go’s solution isn’t perfect. I do wish there were some way of controlling things better for performance-sensitive code. However, for most code that isn’t performance-sensitive, Go’s default hits the sweet spot.
GoLand is really nice to use
At work, I mostly use GoLand for developing Go.
It’s nice that common functionality like Find Usages, Rename Symbol, Annotate with Git Blame just work out of the box, without needing to configure any plugins. The View Call Hierarchy functionality also works okay, but not very well in the presence of interfaces.
GoLand can also optionally fold away if err != nil bodies,
which vertically compresses the code, making it easier to scan.
The concise visualization for fmt.Sprintf and similar calls is also a nice touch,
since Go lacks string interpolation.
The syntax highlighting allows for separate colors for mutable
global variables, as well as nil, which is good.
My current theme highlights those in red, drawing attention.
Performance-wise, GoLand feels a bit snappier than VS Code.
golangci-lint is helpful
golangci-lint is a collection
of checks, with a mix of stylistic checks, lightweight “lint”-style checks
and more non-local “static analyzer”-style checks.
We have a bunch of these enabled in CI, and I run the tool locally as well before pushing changes.
Overall, the checks we have enabled seem to be useful in catching issues, especially minor ones left after tweaking some code in a hurry but forgetting to clean it up.
Playground and runnable examples
Go’s online playground is useful for quickly testing out small code examples. I generally prefer using it over writing small snippets locally in a standalone file, since I can easily share playground links with colleagues if needed.
On a related note, a bunch of the Go documentation has runnable examples (i.e. embedded pre-populated playgrounds), which is a nice touch.
Negatives
People keep saying learning programming languages makes you a better programmer. It really doesn’t. It makes you [better] up to a point. Then it makes you bitter and dissatisfied because you’ll never be able to port those ideas to your day job.
– Aditya Sriram (@deech) (source)
Undesirable semantics for common operations
- The loop iteration variable is reused across iterations, so capturing it by reference (the default for closures) is likely to lead to bugs. Thankfully, this one can be caught by linters to some extent.
deferinside a block executes not at the end of the block, but at the end of the enclosing function.deferevaluates sub-expressions eagerly.
Interrupting flow
When I was using the Go layer in Spacemacs, the errors on unused imports were quite annoying.Maybe I didn’t have the Go layer configured correctly to clean up imports?
Thankfully, this isn’t a problem with GoLand.
Errors on unused variables are annoying as well.
Unfortunately, GoLand doesn’t automatically mark these with _ assignments
(maybe this is configurable?).
This is particularly bothersome when fiddling with tests,
or when temporarily commenting out code paths,
such as when working with code that is unfamiliar.
In most languages, these would be warnings, not hard errors. However, these aren’t warnings in Go, because Go doesn’t have any warnings at all. The official reasoning for the No Warnings Policy includes this incredible zinger:
First, if it’s worth complaining about, it’s worth fixing in the code. (And if it’s not worth fixing, it’s not worth mentioning.)
Every time I re-read this line, it makes me slightly more upset.
There is a time and place for things. 🤌 This is true both for code and for life more generally. Not everything that should be done needs to be done right here right now.
Imagine trying to learn a musical instrument and being berated at every time you play the wrong note. That’s not a way to teach; it’s a way of asserting dominance.
If your friend is crying because they failed an exam, that’s not the time to tell them, “You should’ve studied XYZ more thoroughly.” Do they need to hear that? They probably do, but when they’re crying you should console them. Later, when they’ve calmed down and are trying to figure out what went wrong, that’s when you can give them advice.
😮💨
Cannot make a type in a foreign package implement an interface
In Go, you can only add methods to a type defined in the same package. Non-empty interfaces require adding methods to types. So you can’t make a type in a dependency implement an interface in your package.
I understand part of the reason why the limitation is in place. The problem is that Go currently doesn’t have any syntax to disambiguate if such functionality is added and multiple packages add identically named methods to a type. But that’s a solvable problem; it’s not rocket science.
For example, Swift is very relaxed about this.
In Swift, if you import a library A with type T
and import another library B with protocol P,
even if neither A nor B know about each other,
you can make T conform to P.Except if both A and B are compiled with library evolution,
in which case you get a warning.
Rust is currently somewhat more restrictive than Swift, but it lets you add trait methods to a foreign type if the trait is locally defined. However, Rust is currently exploring if it can be more flexible.
While making things fully flexible is problematic – for example, having distinct implementations for a type + interface pair at runtime would be bad – it would be good if the current restriction was at least relaxed to some extent.
No sum types with exhaustive pattern matching
I was going to share some examples about how sum types would’ve be really useful for work. Instead, how about not just my own work, but everybody’s work?
I tried a search for a code pattern often seen due to the lack of exhaustive pattern-matching in Go:
default:
panic("unreachable")That’s 38.7k hits in the source code across GitHub etc. as of Apr 29 2022. I’ll grant you: some of these must be type switches, which cannot be exhaustive anyways. However, I’m sure I’m missing out on many more switches that ought to be exhaustive but aren’t checked by this query because they have a different panic message.
Given the size of the evidence above, I’m going to skip the example.
No overloading for common operations
Go has a range construct. It works for arrays, slices and maps.
Did you write your own hash table type and want to iterate over it?
Well, too bad, you can’t have the nice range syntax.
Or did you want to access elements from that map?
Well, again, too bad, you can’t have the nice [...] syntax.
Having these (and many other) operations be special-cased to types in the standard library makes the experience of using custom data structures more cumbersome than it needs to be.
This isn’t just an abstract problem. At work, we have some map
and set types which are small-size optimized. The code that uses
these is needlessly verbose because of the lack of syntax overloading.
No standard set type
The standard library has a large number of modules,
but lacks a set type for some reason.
Yes, one can use map[T]struct{}, but that feels needlessly cumbersome.
(Yes, I know I can use a third-party package…)
Given that Go 1.18 added support for generics, I hope that commonly useful collection types like sets will be added to the standard library in upcoming versions of Go.
No anonymous interface compositions
The Go standard library defines a bunch of interfaces
which are essentially just compositions of other interfaces.
For example, the io package contains:
ReadCloserReadSeekerReadWriterReadSeekCloserReadWriteCloserYes, there’s noWriteSeekCloserorReadWriteSeekCloser.
ReadWriteSeekerWriteCloserWriteSeeker
The way these work is that you have a definition with “embedded interfaces”:
type ReadSeeker interface {
Reader
Seeker
}And any type that satisfies the embedded interfaces will also satisfy
the ReadSeeker interface.
The problem with this approach is that if you want to use a pair of interfaces to describe an API somewhere, you need to define a new combined interface. Defining that new interface isn’t a lot of work, it’s just that it seems like pointless busywork. Maybe I’m missing some reason why this limitation exists…
In contrast, Swift allows composing protocol types with &
(e.g. Codable which allows for serialization and deserialization)
and Rust allows trait combinations with +.
Now that Go 1.18 has added support for generics with constraints, I suspect that this problem will come up more often as more generic code is written. So maybe this will be fixed in the future?
CORRECTION: A colleague pointed out that you can directly do something like:
func f(x interface {
io.Reader
io.Seeker
}) {}without defining the type separately. This is consistent
with how anonymous structs can be used. However, I’m not
a fan of this syntax; it feels very verbose given that
gofmt will splat the different fields across different lines.
It would be nicer if you could write it in a more compact way.
Naming conventions
The names for symbols in the Go standard library, as well as the various tooling flags leave a lot to be desired. Broadly, the problems fall into three buckets:
- Using short names without good reason, such as for infrequently used public symbols. C used to have short names because linkers couldn’t cope with symbols longer than 8 characters. That restriction no longer applies though.
- Naming being very different from other languages, without good reason.
- Names being misleading, in that the actual behavior does more or less than what you’d expect just by looking at the name.
Here are some examples:
fmt.Println(...)in addition to putting a newline at the end, also puts spaces in between arguments.filepath.Clean()is not calledfilepath.Canonicalize()orfilepath.Normalize(). Moreover, “clean” seems to imply that something is “dirty” which is being fixed, but filepaths with some.and..can hardly be called “dirty.”filepath.Join(...)doesn’t just concatenate paths, optionally putting a separator in between, but also callsfilepath.Clean(...)on the result.The
tarpackage has a header type calledtar.TypeReg, whereRegis short for “regular file”, and a header type calledtar.TypeLinkfor hard links. However, some other header types do use full names, such astar.TypeSymlink.exec.LookPath(file string)searches for an executable namedfilein directories named by thePATHenvironment variable.PATHought to be capitalized according to the case conventions followed elsewhere, and the immediate verb after in the doc comment is “search” (~ “find”). So why not have the declaration be one of:FindInPATH(executableName string) OR FindExecutableInPATH(name string)instead of
LookPath? IME, “find” is a much more common verb prefix for function names compared to “look” (usually used as “lookup”).go mod tidy: the verb “tidy” to me means that it will potentially rearrange stuff but not add/delete things. Moreover, it sounds like an optional thing. Well, that’s not whatgo mod tidydoes. It downloads dependencies, adds them to thego.modfile, and also removes unused dependencies from thego.modfile.All of
go get’s flags[-d] [-t] [-u] [-v]do not have corresponding longer versions.The canonical Go package for describing Go modules is called
module, and it has a type calledVersiondefined as:type Version struct { Path string Version string }So this type will be referred to as
module.Versionby code outside this package. However, if you haven’t seen the type’s definition, it is easy to mistakenly think that the type describes only a version. But it has aPathtoo!Why not name this type
WithVersionorDependencyorID? That way, the likelihood of misunderstanding would be reduced.This one hasn’t affected me personally yet, but it deserves a special mention. The default Go compiler is called
gc.It should be clarified that the name “gc” stands for “Go compiler”, and has little to do with uppercase “GC”, which stands for garbage collection.
I have not done any git spelunking to figure out if this was meant as a shitpost-style naming thing (“hohoho, all ill-formed Go code is garbage”) or if it was done to save a single ‘o’ character somewhere or something else.
Odd choice of terminology
Go documentation often uses non-standard terminology in situations where well-established terminology exists. Some examples:
- The
regexpackage repeatedly uses “submatch” and “parenthesized subexpression” in its docs, even though the more common term is “capture group” (which is mentioned just once). - The documentation for the
stringspackage repeatedly uses “Unicode letters” instead of the more standard term “codepoints.” - Special character sequences like
%sin format strings are called “verbs”, even though “format specifiers” is the more common term of art in other languages.
Struct layout is based on declaration order
Go does struct layout of fields based on declaration order.At least, for monomorphic structs. I have not checked how it works with generic structs.
This has two unfortunate side effects. First, a bunch of code is needlessly less efficient that it needs to be. Second, if you do care about efficiency in certain parts, you need to do the layout “by hand”, potentially needing to put conceptually related fields further apart to reduce memory footprint.
Poor compiler diagnostics
In terms of diagnostics, the Go compiler has a lot of room for improvement. It’s not even as good as Clang, let alone Rustc.
In most (all?) cases, it does not make any attempt whatsoever to provide textual hints on how to fix the code. Some examples:
- If you make a typo in a type name, there won’t be any suggestion on how to fix it.
- If you write a type name without the package qualifier, there won’t be any suggestion on which package it comes from.
- If you shadow a package name with a local variable
(not hard to do accidentally since package names are lowercase,
especially with package names like
bytes), there’s no hint when trying to access a function from the package (which gets interpreted as a field access on the local).
I’m not even talking about IDE-integrated fix-its here, where the suggestion manifests as an action that edits the code. Writing textual suggestions is much simpler. Why not do that at least?
It’s unfortunate that the compiler diagnostics have not seen more attention. One of the reasons why Go was designed to be simple was to be able to on-board junior developers quickly. Surely, more useful compiler diagnostics are important to get junior developers get unstuck quickly?
I’ve had this running hypothesis for a while now, that diagnostics are one of those compiler areas which:
- Are consistently under-invested in, even when people claim to value that area.
- Fundamentally requires people who deeply care about diagnostics to make a difference in the long term.
As one data point, when I worked on Swiftc (mid 2019 - late 2021), there wasn’t a single person dedicated to working on diagnostics. There were people working on type-checker performance, and those helped surface existing diagnostics in some situations which would previously time out. Different people did fix diagnostic bugs from time to time. But it wasn’t someone’s job to do it. From the outside, it seems like Go is in a similar boat. 😬
Odd doc conventions
Go has a convention that doc comments must begin with the name of the entity they describe. English is not my first language, and even I can tell that this makes function documentation read in a bizarre way. Consider an example: [^edit]
// DecompressTarball decompresses the tarball r and saves the output in outDir.
//
// <other stuff>
func DecompressTarball(r io.Reader, outDir string) error(EDIT: In an earlier version of this post, this function was previously not exported, which was unintentional.
I’ve fixed the spelling from decompressTarball to DecompressTarball.)
You have needless repetition: “decompress” and “tarball” both appear twice in the first line without good reason.
No other language that I know of follows this style. If someone is looking at the documentation for a symbol, they already have the symbol name available. So why repeat it?
Limited markup support in godoc
godoc only supports a few markup features. In contrast, both Rust and Swift support a superset of CommonMark. Less popular languages like OCaml and Haskell have Odoc and Haddock respectively, which are also quite featureful.
There have been some improvements recently on this front, with support for headings, lists and links. It’s kinda’ surprising that it took over 10 years to add support for these though! Given that link support is so new, the number of links in the existing docs is quite low.
According the RFC linked above, to avoid “space-counting subtleties like Markdown”, the list syntax doesn’t support nested lists. I don’t know of any other programming language which has a standard documentation tool that doesn’t support nested lists.
Also, embedding images is not supported because the “complexity is in direct conflict with the primary goal” where the primary goal is to “prioritize readability, avoiding syntactic ceremony and complexity.”
I hope that more of these limitations are removed over time.
Documentation in some cases is not well-organized
As an example, the pprof docs are scattered in multiple places:
- The official pprof README has some docs. The “Fetching profiles” section (which covers how to record a profile) is near the bottom whereas information about analysis is near the top. This doesn’t make much sense to me; one first needs to record a profile before being able to analyse it.
- The net/http/pprof package docs covers some things.
- The runtime/pprof package docs cover some more things.
It starts out with a long code example.
After that, it casually mentions that the package
net/http/pprofalso exists, without giving a clear recommendation on whenruntime/pprofshould be used overnet/http/pprof.
Struct initialization syntax
Go supports two related syntaxes for struct initialization:
- Positional: Lower readability,Ameliorated by using an editor with inlay hints, such as GoLand.
but you get a compiler error if you miss a field. - With field names: Higher readability, but unspecified fields are zero-initialized.
So you need to pick readability xor completeness. Too bad if you want both!
Because of these factors, you probably want to maintain the following discipline:
- Use positional initialization for locally-defined structs and use an editor with inlay hints. This way, you’ll get a compiler error when you add a field.
- Use field names when initializing a third-party struct, so that your code doesn’t break if upstream adds a field in the future.
Pre-main initialization and global mutable state are common
We had a “fun” bug at work, where my colleague moved a couple of definitions from one package to another, and that broke a bunch of tests. He spent a bunch of time investigating this before the issue was resolved. How did this problem come up?
The tests was doing some stuff with timezones.
The old package that the function was in imported some other package,
which had an init functionFor people unfamiliar with Go, an init function runs before main,
and is not explicitly called.
This functionality is similar to global constructors in C++,
except that the relative order is more well-defined.
that modified the current timezone,
which is a global variable.
The new package that the function was moved to did not import the
timezone-modifying package.
The problem with init functions is that the
dependencies across them are not clear.
Instead, a more explicit design that would be more helpful IMO
would be making init functions “must use.” A library would
have two options:
- Call the
initfunction of an imported package from your owninitfunction. - Discard the imported package’s
initfunction with_.
An executable would have the same restriction, with the additional
requirement that the executable’s own init function must be
discarded by assigning to _ or called as the very first statement of main.
Is that a perfect design? No.
For one thing, under such a scheme, adding an init function to a library which didn’t have
one before becomes a breaking change.
However, a design along these lines would make it much easier to debug
and understand issues related to init functions.
Conflating useful default values with useful zero values
Go has a built-in notion of zero values for all types,
which is defined recursively as one might expect.
Integers use 0, floats use 0.0, strings use "", pointers, functions, slices and maps use nil
– you get the idea.
Moreover, it is possible to safely create zero values of user-defined types even when there is no explicit API to do so:
- The default JSON marshaling functionality will happily construct zero values of types if the field is missing (making it not possible to distinguish missing keys vs keys explicitly mapped to the zero value, without a bunch of extra work).
- A receive from a closed channel returns the zero value.
- Slices can be zero-initialized.
This means that if you maintain a library which contains a type whose zero value isn’t meaningful (and not constructible through the library’s API), your two options are:
- Your library’s functions assume that zero values are never passed in. So if some unfortunate programmer passes in a zero value to one of your functions, chances are that their program will go wrong in a hard to debug manner (and they might even file an issue on your library’s issue tracker!).
- Your library’s functions are defensive in checking for zero values and throw an error or panic on getting one. This incurs overhead for all library users.
Billion dollar mistakesA GitHub search for issues mentioning nil dereference errors gives 24k hits as of Apr 29 2022.
and defensive programming aside,
somewhat oddly, zero values are considered good in Go!
In his talk Go Proverbs,
Rob Pike suggests “Make the zero value useful” as a guideline.
He gives examples of how the standard library uses this principle to good effect.
What Pike doesn’t mention is that it’s much easier to have meaningful zero values for abstract structures, such as those found in a standard library, as compared to narrow domain specific types, such as those in an application.
The other problem is that the zero value is entirely determined by the language and not by your code! If you have a struct with a pair of string fields, the zero value of that struct has two empty strings. You can’t change that.
On the other hand, in (say) Rust, you can:
- Choose to derive the
Defaulttrait - Implement the
Defaulttrait manually - Choose not to implement the
Defaulttrait, because maybe there is no good default.
You have options.
In essence, because Go conflates the notion of “default values” and “zero values”, it ends up emphasizing the wrong concept.
Serialization
As I mentioned earlier, the default deserialization setup which zero-initializes fields makes it impossible to distinguish fields that are unset from those which are set to the zero value (without doing a bunch of extra work).
Additionally, if you accidentally add struct tags to private fields (incorrectly assuming that is enough to serialize/deserialize them), you will silently get the wrong result (with zero values) instead of a runtime error.
Inconsistent behavior
nil
nil is sometimes equivalent to an empty collection
but sometimes causes a runtime crash.
var a []int // initialized to nil
_ = append(a, 1) // OK
var m map[int]int // initialized to nil
m[0] = 0 // panic: nil dereferenceIt’s not super clear to me whether there is some systematic rule
governing when nil causes a crash when using a built-in operation.
Are crashes specific to write contexts and non-crashes
specific to read-only contexts? I don’t know.
Substitution
x := ""
_ = &x // OK
_ = &"" // invalid operation: cannot take address of "" (untyped string constant)Is this disallowed because there are two possible reasonable behaviors here (pointer to static vs non-static data)? I don’t know.
// type S struct {}
_ = &S{} // OK
f := func() S { return S{} }
_ = &f() // invalid operation: cannot take address of f() (value of type S)Such a restriction would make sense in the context of a language with manual memory management like C or C++, where creating a reference to a temporary from a function call would increase the risk of use-after-free. However, Go has a GC so I don’t get why this is disallowed.
Literals
a := [][]int{ {0, 1} } // OK, no []int needed inside
type S struct { s []int }
b := S { []int{0, 1} } // OK
c := S { {0, 1} } // error: missing type in composite literalFrom a type-checking perspective,
the type of the literal should be available in the type-checking context
based on the first field of S,
so it’s not clear why specifying []int is needed for the literal.
Clearly, there are situations in which omitting the type of a composite
literal is permitted. So why not allow omitting it here too?
func f(_ []int) { }
func g() { f([]int{0, 1}) } // OK
func h() { f({0, 1}) } // syntax error: unexpected {, expecting expressionThis seems even more strange; instead of giving a “missing type in composite literal” error, it gives a syntax error.
The oddness around literals and lack of builtin support for sets
means that working with map based sets requires
sometimes spelling out struct{}{}, which feels like too many
characters for describing a whole lot of nothing.
make
Initialization with make behaves differently for maps and slices:
m := make(map[int]int, 10) // capacity = 10, length = 0
a := make([]int, 10) // capacity = 10, length = 10 (zero initialization)
b := make([]int, 0, 10) // capacity = 10, length = 0So not only is there an inconsistency, the more common operation has a longer spelling.
Inconsistency and extra keystrokes aside, I think this creates
a greater risk of bugs when code is being changed.
One of the common situations where you want to allocate a slice
of a known capacity comes with a code pattern like:Let’s ignore the fact that the zero initialization is likely
just wasting cycles because the memory is immediately going to
be overwritten.
buf := make([]T, length)
for <...> {
// set elements of buf one-by-one
}The shorter make form here is a footgun waiting to be tripped on.
The problem is that if the loop body grows long
and someone adds a break or continue clause,
they may miss realizing that they need to modify the make too.
That way, the slice will have a bunch of zero values
which is quite likely undesirable.Ask me how much time I spent on a bug caused by this failure mode.

Instead, if there were a separate make_zeroed built-in:
- The common usage would have the shorter spelling.
- This footgun wouldn’t exist.
- The behavior of
makewould be more consistent.
Public identifiers in tests are not available to other tests
This is probably best explained with a diagram.
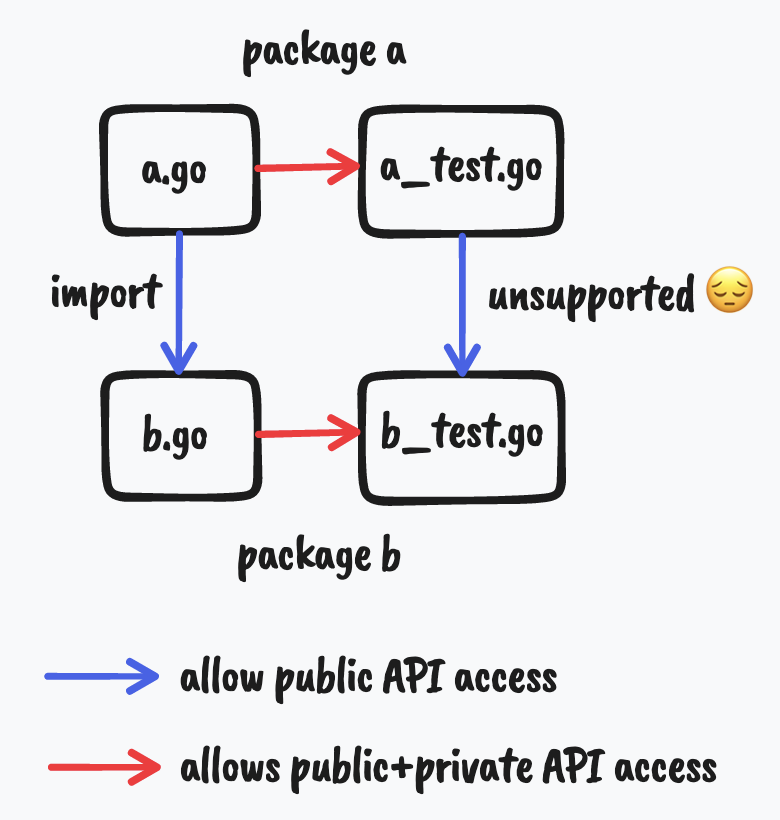
There are two packages a and b, and b imports a.
Thanks to this import, b has access to the public API from a.go.
a_test.go is a testing-only file, and has access to private APIs from a.go. Similarly for b_test.go.
However, importing a in b_test.go doesn’t provide access to the public APIs
in a_test.go. This means that if you want to export functionality
to help downstream modules test stuff involving types defined in your package,
you need to expose them as public APIs from your package.
Why not allow b_test.go to use public APIs from a_test.go?
That would make it easier to reuse test code.
Keep chugging along in the face of logic errors
In some cases, Go will not panic in the presence of logic errors. Couple of examples that come to mind:
fmt.Sprintfwill happily insert(MISSING)if a format specifier (such as%s) does not have a corresponding argument.- Sends and receives to a
nilchannel block forever.
If there were panics due to these, you could detect the problem more quickly.
Language simplicity is put on a pedestal
If you watch talks about the design of Go, or on best practices how to write Go code, simplicity and readability are recurring themes. These come up so often as design justifications that I had to mention it here.
For example, YouTube recently recommended a 2015 talk to me titled “Simplicity is Complicated”, by Rob Pike. Here’s some of the content from one of the slides, which I think broadly encapsulates what I’ve seen echoed elsewhere too.
The code is harder to understand simply because it is using a more complex language.
Preferable to have just one way, or at least fewer, simpler ways.
Features add complexity. We want simplicity.
Features hurt readability. We want readability.
Readability is paramount.
I empathize with the sentiment to an extent. There’s a limit to how gnarly type errors (as an example) you can get if you don’t have generics, which were only added recently. Fewer gnarly type errors, other things being equal, make for a better developer experience.
However, the “other things being equal” is an important caveat. Given how language features have knock-on effects, most often, other things are not equal. If language simplicity is achieved at the cost of refactorability, debuggability or higher risk of crashes in production – then maybe it should not be put on a pedestal but rather treated as a guiding principle that is sometimes useful.
More succinctly, simplicity is a means to an end, rather than an end in itself.
As an example of “simplicity” in one case making a bunch of other things more complicated, here is an actual message I sent in the work Slack some time back:
Some obstacles I’ve faced quite a few times when reading our code [using pointers] include:
- It’s not clear if a value that is passed via pointer is intended to be mutated or not. (const-ness / mutability) (maybe it’s passed via pointer just because the size of the struct is large?)
- It’s not clear if a value that is passed via pointer may be
nilor not in practice (particularly true for pointer fields in structs) (nullability)- (Less common) It’s not clear if the caller is free to continue using the point if the callee is intended to “consume” the value (borrowing / ownership)
In Rust (as an example), these would all be distinct types
&T(borrowed immutable/shared)&mut T(borrowed mutable/unique),Box<T>(owned mutable/unique), with potentially anOption<>wrapper ifNone(~nil) is allowed.Anyone else also run into this kind of problem when reading code?
I’m not sure what a good solution to this looks like (maybe we can have some coding conventions around pointers in our Go style guide?), but I’m curious if other people have strategies for figuring this out faster, or perhaps are following some unwritten conventions in different parts of the codebase.
Here are the responses:
- This is also a frequent headache for me. Here are some conventions which I follow to avoid this problem: <…> (+3)
- [In addition to the above] If for any reason, the mutation is done in the original object, docstring must make it clear.
- Yep … it almost feels like picking up a bunch of random folklore traditions that make no sense. Joking aside, I understand that Go tries to be super minimal, but the problems Varun has described are totally real. The solution relies on conventions, which are hard (close to impossible?) to guarantee. <…>
So it’s not just me who has this problem, it’s other people too. And all of these people responding have more experience (both Go and otherwise) than I do.
Miscellaneous papercuts
AFAIK, godoc markup doesn’t support inline code (backticks in Markdown). This means that for system fonts which make distinguishing between I (uppercase i) and l (lowercase L) hard, reading function names in running text can be a little cumbersome, as they are rendered in non-monospace fonts. Monospace fonts are usually better at distinguishing these characters IME.
Normally, this doesn’t matter for English text, since the letter is clear from context, but it is a little tricky for function names specifically because Go function names frequently do not use full words.
The
flagmodule in the standard library, which is commonly used for argument parsing, outputs help text to stderr instead of stdout, even when the user has explicitly requested the help text. This means that for every Go binary that you are using, you almost certainly need an extra2>&1redirection when piping the output of--helpto a pager.I once accidentally ran
go test cmd(we have acmddirectory at the root of our repo at work) and that started running the compiler’s tests.ok cmd/addr2line 2.998s ok cmd/api 5.510s ? cmd/asm [no test files] ? cmd/asm/internal/arch [no test files] ok cmd/asm/internal/asm 1.411s ? cmd/asm/internal/flags [no test files] ok cmd/asm/internal/lex 0.008s ? cmd/buildid [no test files] ? cmd/cgo [no test files] ? cmd/compile [no test files] ? cmd/compile/internal/abi [no test files] ? cmd/compile/internal/amd64 [no test files] ? cmd/compile/internal/arm [no test files] ? cmd/compile/internal/arm64 [no test files]I don’t understand why this is a desirable default. Most Unix commands that I know of do not behave differently when passing a path as
./XvsX, so it’s unclear whygo testbehaves this way.
Closing thoughts
When I was working on the first iteration of this section, I was not really sure what to close with. I’d come up with some joke hypotheses:
- Go as reified mental scar tissue, resulting from injuries sustained by maintaining Java and C++ code at Google.
- Go as an absurdist programming language, which forces the programmer to reconcile the contradiction between their desire to seek a set of consistent design principles behind the language, with their inability to find them.
- Go as a programming language from a timeline other than the Steins;Gate timeline.
As you can probably tell, it wasn’t really going anywhere good.
Later, while I was doing background research around previous posts on Go, and people’s responses to them, one comment stood out to me:
I think Go follows the Worse Is Better principle. Which could explain why simplicity was chosen above correctness and completeness.
To be clear, “Worse is Better” sounds quite pejorative. I’m not endorsing the term. It’s also called “New Jersey style” which I guess sounds less pejorative (unless you’re from New York). Exact names aside, the description on the Wikipedia page is illuminating, so I’m copying it below:
a model of software design and implementation which has the characteristics (in approximately descending order of importance):
Simplicity: The design must be simple, both in implementation and interface. It is more important for the implementation to be simple than the interface. Simplicity is the most important consideration in a design.
Correctness: The design should be correct in all observable aspects. It is slightly better to be simple than correct.
Consistency: The design must not be overly inconsistent. Consistency can be sacrificed for simplicity in some cases, but it is better to drop those parts of the design that deal with less common circumstances than to introduce either complexity or inconsistency in the implementation.
Completeness: The design must cover as many important situations as is practical. All reasonably expected cases should be covered. Completeness can be sacrificed in favor of any other quality. In fact, completeness must be sacrificed whenever implementation simplicity is jeopardized. Consistency can be sacrificed to achieve completeness if simplicity is retained; especially worthless is consistency of interface.
This is contrasted with the “MIT approach”:
Simplicity: The design must be simple, both in implementation and interface. It is more important for the interface to be simple than the implementation.
Correctness: The design must be correct in all observable aspects. Incorrectness is simply not allowed.
Consistency: The design must be consistent. A design is allowed to be slightly less simple and less complete to avoid inconsistency. Consistency is as important as correctness.
Completeness: The design must cover as many important situations as is practical. All reasonably expected cases must be covered. Simplicity is not allowed to overly reduce completeness.
When I read this page, I felt a light bulb go off in my head.To be clear, I’m not saying that Go follows the New Jersey style exactly,
or that Swift/Rust follow the MIT approach exactly.
However, in broad strokes, I do think those two approaches are somewhat fitting descriptions.
This is probably the point where I progressed from the bargaining
stage of the Kübler-Ross cycle I was on.
One of the things I realized that I was refusing to internalize was that the Go team prioritizes keeping implementation complexity down a LOT more than folk implementing other mainstream languages that I know of.
To half of my brain, this statement seems absurd at face value. That half indignantly insists, “Of course, complexity should be moved into the language as much as possible if it makes things better for language users! There are many more language users than implementors!” I suspect this is partly an outcome of and partly a cause for why I ended up working on Swift.
The Swift toolchain goes to ridiculous extents
to offload complexity from Swift developers.
From an entire compiler subsystem for first-class Objective-C interop,
to the sophisticated handling for strings,
to a type-checker that needs to handle people trying to constantly push its limits
with all sorts of nonsense interesting APIs,
Swift takes on a LOT of complexity.
Juggling this complexity imposes a serious mental cost for people working on Swift.
So I sympathize with the desire to keep the implementation as simple as can be.
I get it.
At the same time, I think for me, the MIT approach is so much more closer to how I think about software design and correctness, that even though I can “get” the New Jersey style in the abstract, it’s very difficult for me to internalize it. There is a serious cognitive effort that is needed to overcome the impedance mismatch between a conception of “how things ought to work” and the reality of “how things actually work.”
This reminds me, if you haven’t seen Bryan Cantrill’s discussion on Software as a reflection of Values, you should probably do that. I should also probably rewatch it, and hopefully advance to the acceptance stage. Or maybe it doesn’t matter; I will likely be working a lot more with TypeScript and other languages over the next few months, so it is unlikely that I will post more long-form Go stuff after this.
In the meantime, please be nice to each other.