Deeper theories of program design
Target audience: Programmers with 5+ years of work experience.
If you’ve participated in online discussions on programming, you may have noticed that nuance and deep analyses are often in short supply in comparison to pat answers that rely entirely on subjective criteria or socially-accepted memes such as “It depends.”
Well, you might say, that’s not specific to programming, and it’s not specific to online discussions. People often rely on System 1 thinking in real life too. To that, my response is:
- I agree with you; those are fair points.
- I’m talking about programming because I have experience as a programmer.
Unfortunately, the problem doesn’t end with online discussions. I believe many books on programming, including well-respected ones, fall into the same trap.
I believe there are much deeper and richer theories of program design which we are yet to understand. But I believe we can discover them through reasoning, and test them as hypotheses against the real world.
This post is my attempt at illustrating this point by doing a deeper analysis of a seemingly “simple” situation.
Deleting some files
In the book A Philosophy of Software Design, John Ousterhout has a chapter
called ‘Define Errors out of Existence’I’ve seen multiple people criticize this chapter. For example, Carl Brown (aka ‘Internet of Bugs’) has a book review which discusses the NFS example in this chapter. The point here is not about whether analysis itself is correct/wrong, but about the method of analysis presented, and to contrast it with a different way of thinking.
which includes the following example:
Windows “does not permit a file to be deleted” if it’s open in a process.
- This causes frustration for developers and users, requiring users to find and terminate the process using the file.
- Out of frustration, users may give up and reboot the system to delete the file.
- EDIT(2025-07-22): In the Lobsters discussion thread, Alex Kladov pointed out
a couple of more practical examples of where this can bite a program:
- Deleting directories can require a large number of retries if files inside the directory are in use.
- Updating a binary in-place while it is running requires complex workarounds.
In Unix, a file can be deleted successfully even if the file is in use by some other process. Once the deletion succeeds, the old file can no longer be opened, and a new file with the same name can be created. Processes which already have the file open can continue to read and write to it. Once these handles are closed, the data for the file is freed.
This means that there are no errors for the process doing the deleting. This also means that in a language like Java, where errors are mostly manifested as exceptions, an exception won’t be thrown by the deletion operation in this particular situation.
- Ousterhout considers this behavior to be more “elegant.”
Ousterhout cites his personal experience as one reason to support Unix’s model. (Sec 10.3 “It may seem strange that Unix allows a process to continue to read and write a doomed file, but I have never encountered a situation where this caused significant problems.”)
A couple of days back, I was close to running out of disk space on my work MacBook. I don’t recall the exact order of operations that I did, but at one point, I was having the following operations running concurrently, solely through the UI:
- Moving some large folders to Trash.
- The ‘Empty Trash’ operation.
During that time, the ‘Empty Trash’ operation paused to tell me that a folder was in use, and asked me whether I wanted to Skip, Stop or Continue.
How should we theorize about programs?
In the keynote How many oranges 🍊…? at PyCon India 2024,
James Powell narrates an example where he asked a relative the question
“How many oranges does it take to make a glass of orange juice?”
and the relative promptly replied with “It depends on the size of the oranges,”
which really triggered Powell.Powell’s delivery is much better than my meagre summary indicates; I highly recommend watching the talk if you have the time to do so.
Powell points out how answering questions involves an active theory of mind, and that discussions need to resolve questions such as what the asker already knows and doesn’t know. Powell laments about how sometimes technical discussions end up in truisms such as “It depends” or “It’s a series of trade-offs.”
Powell talks about the idea of foundational theoretical frameworks for program design, which will in general have a mix of qualitative and quantitative aspects. One example he introduces is the usage of positional arguments and keyword arguments in Python, which is often a confusing topic for beginners.
All the following are possible in modern Python:
- You can require the caller to pass the argument by position.
- You can require the caller to pass the argument by keyword.
- You can allow the caller to pass the argument by position or keyword.
Powell articulates the following two-fold core proposition:
- ‘data arguments’ (e.g. a CSV file to be opened) should be passed positionally
- ‘modal arguments’ (e.g. settings/configuration options) should be passed by keyword
Powell walks through several examples of APIs using this idea.
For example, if there is a function which reads a CSV file,
modal arguments passed as booleans or strings may be confusing
at call-sites if there isn’t a keyword at the front (e.g. True vs headers=True),
but data arguments will generally be clear from context
(e.g. read_csv(users_file, ...) or a literal read_csv('../test/users.csv', ...)).
Powell also describes APIs which violate this, and run into problems.If you’re trying to think of counter examples of APIs which do not satisfy this but are still intuitive, I recommend pausing that thought until after going through the video.
Powell also talks about certain dogmatic expressions such as Don’t Repeat Yourself (DRY) which lack substance.
If the theoretical framework we’re coming up with is actually true, it actually has some substance, then it allows us to predict things, it allows us to extrapolate, and it allows us to distinguish between two things that might look the same.
Powell points out one of the key techniques for building a theoretical framework is by finding the boundaries of a problem, to see where distinctions arise.
For more details and examples, I recommend watching the talk. For now, let’s try applying these ideas to the file deletion example.
File deletion - re-visited
Consider the people who designed the filesystem APIs for Windows and Unix, as well as the people who designed the Finder behavior of prompting someone in the presence of concurrent modifications in subfolders of Trash.
What is your theory of mind for these people?
I don’t know who these people were, and what constraints they were operating under, but it seems reasonable to assume that they were all at least somewhat smart, and they had at least some combination of API usability, end-user functionality and potentially backwards compatibility in mind when they designed the functionality that they did.
So why would different groups of smart people arrive at different solutions for seemingly the same problem of how to handle concurrent read/write operations along with deletion operations for a piece of data?
In an attempt to answer this question, let’s look at a slightly different example.
Let’s say you have a single program, and different threads in that program are trying to do concurrent operations, at least one of which is a write operation, on a shared piece of data. How would that work?
Concurrent modifications in other contexts
If you look at existing programming language toolchains, here are the potential ways they support programmers in dealing with concurrent mutation in the presence of sharing:
- Zero support (i.e. allow data races).
- Provide dynamic race detectors which can run when running tests, or maybe these are even usable in production.
- Forbid concurrent mutation altogether.
- Provide specialized atomic operations.
- Provide dedicated types to control entry to critical sections, such as locks and semaphores.
- Provide types for message passing, such as channels, queues and actors.
- Provide native support for software transactional memory.
A single language (toolchain) may support multiple distinct approaches to deal with concurrent mutation.
If you look outside the context of programming languages, and look at databases, you’ll find concepts such as:
- Transactions, along with different isolation levels
- Eventual consistency
- Conflict-free replicated data types (CRDTs)
- Distributed transactions
- Consensus algorithms
and more.
That’s a lot of words, and maybe you don’t know all of them. That’s OK, I’ll explain the necessary bits in more detail as we go.
How does the above help with understanding file deletion?
Metaphors for concurrent file modifications
The Windows approach for returning an error when trying to delete a file
that is being used has lock-like semantics. Specifically, if you were to
conceptualize each file as having an RW lock,
then file deletion requires having a write lock.The point here is about the semantics of the interface, not about whether the implementation of that interface utilizes locks or something else.
If someone else has acquired the same lock in read or write mode, you cannot acquire the lock in write mode until they release the lock, because that’s what it means to be using an RW lock. So you need to wait for them to give up the lock, or if you’re not so inclined to be polite, then you terminate them.
Why would it make sense for someone to design file system accesses to have lock-like semantics? One answer is safety. Having lock-like semantics prevents different processes from accidentally modifying the same file at the same time. An RW lock allows multiple processes to read from the same file concurrently, avoiding pessimizing the common case.
OK, so Windows’s file deletion behavior is like an RW lock;
what about the Unix behavior? If you squint a bit,
the Unix behavior is somewhat similar to database transactions.
Consider the following historyOperations on the same line are concurrent. Operations on consecutive lines have a happens-after relationship. ‘Tn’ is a transaction ID.
of transactions
for a database storing key → value pairs:It doesn’t matter whether the database is a key-value store, relational or something else, so long as it can store key-value pairs.
T0: begin
T0: write "k" "x"
T0: commit
# Run 2 transactions concurrently
T1: begin, T2: begin
T1: read "k", T2: delete "k"
T1: write "k" "y", T2: commit
# T3 starts after T2 commits
T3: begin
T3: read "k"
T1: read "k"
T1: commit
T3: commitIf you run the above operations in a database like Postgres, you can get the following output:
T1: read "k" -> "x"
T3: read "k" -> (not found)
T1: read "k" -> "y"So it’s as-if each transaction is operating in a bubble of its own.
So is that the end of the story? Unix filesystem operations are like DB transactions, and Windows filesystem operations are like locks, and it is generally well understood that transactions are a more high-level primitive than locks, so it is justified to believe that Unix filesystem semantics are generally more useful and “high-level” compared to Windows filesystem semantics?
No. We need to go deeper.
If you’ve been paying attention, you’ll recall the following phrases just a little bit earlier: “Transactions, along with different isolation levels” and “you can get the following output.” So what’s that about?
Down the transaction semantics rabbit hole
Turns out, database transactions are not just “one thing” but they can be run with different semantics.
Specifically, the isolation level of a transaction describes the guarantees that the database makes about reads and writes observed by transactions. For example, Postgres supports 4 different isolation levels:
- Read Uncommitted: A transaction can read data written by other uncommitted transactions.
- Read Committed (default): The current transaction can read data written by other committed transactions, including commit operations concurrent with our own execution.
- Repeatable Read: The current transaction is guaranteed to read values which were either committed before the transaction started, or modifications made by the current transaction.
- Serializable: Everything happens as-if the transactions happened in some serial order.
Normally, when people think about transactions, I’d wager they mostly think about the Serializable level, because that’s the simplest one to understand. But most mainstream databases either do not support Serializable, or do not default to Serializable level isolation even if they support it.
As one example of a weird situation that can arise at isolation levels weaker than Serializable, here is an example from Martin Kleppmann’s excellent talk Transactions: myths, surprises and opportunities at Strange Loop (RIP):
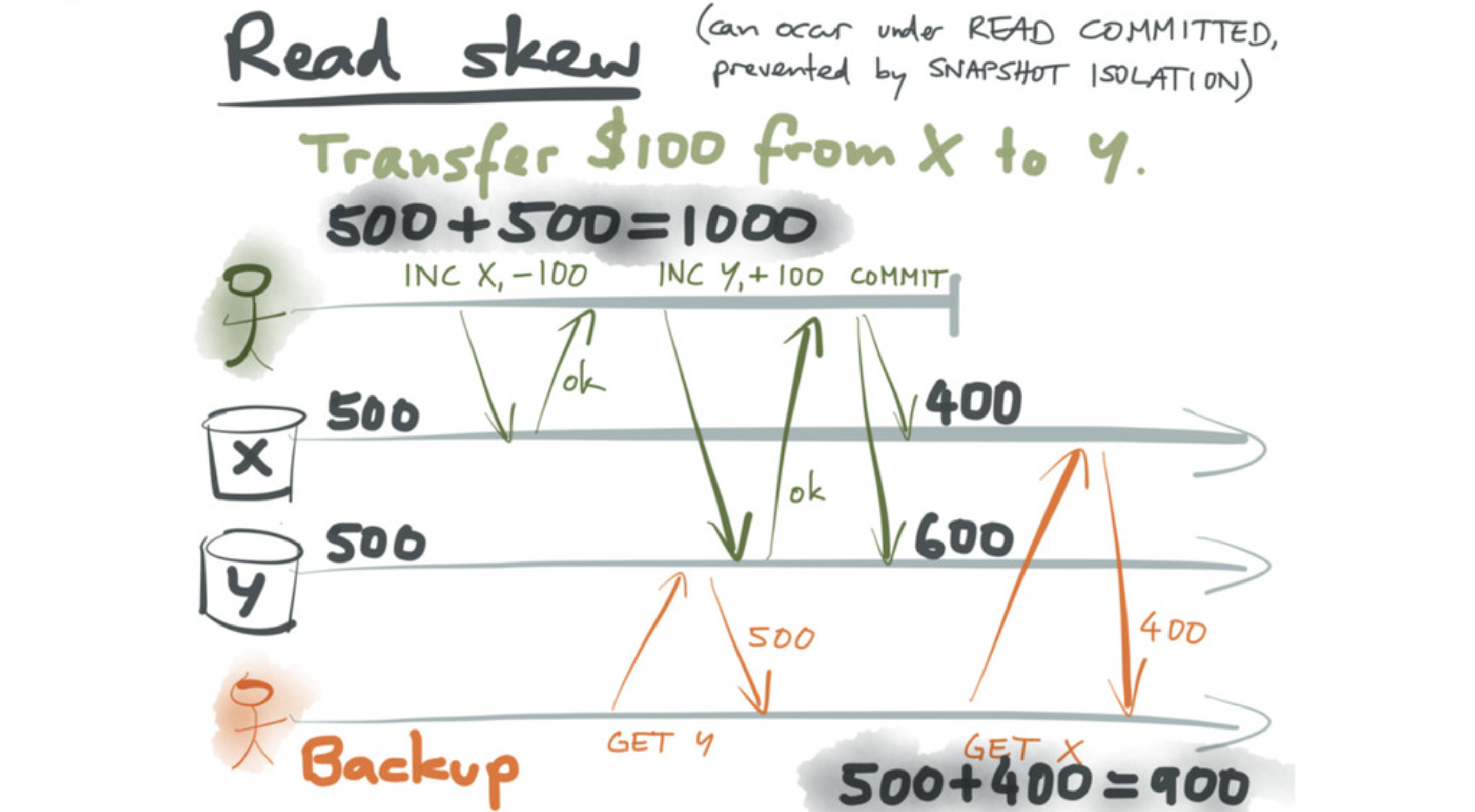
OK, so Postgres defaults to Read Committed, and Read Committed can lead to anomalies in some situations. What about the next level up - Repeatable Read?
Kleppmann describes a class of issues (under the name of write skew) which are allowed under Repeatable Read. These generally follow the pattern of:
- Read some data from the DB.
- Make a decision or perform a calculation based on that data, often in application logic.
- Write the final decision/result to the DB.
Kleppmann gives the example of doctors being on-call, and you want to ensure that at a given time, at least one doctor is on-call. Here is a potential transaction history for that.
# Initial setup
T0: begin
T0: write "alice" "available"
T0: write "bob" "available"
T0: commit
# Both Alice and Bob are checking if they can go home
T1: begin, T2: begin
T1: read "alice", T2: read "alice"
T1: read "bob", T2: read "bob"
T1: write "alice" "unavailable", T2: write "bob" "unavailable"
T1: commit, T2: commitThis succeeds under Repeatable Read, violating the desired invariant. However, under Serializable, we get an error.
T1: read "alice" -> "available"
T2: read "alice" -> "available"
T2: read "bob" -> "available"
T1: read "bob" -> "available"
T2: ERROR 40001: could not serialize access due to read/write dependencies among transactionsOK, so Repeatable Read can also lead to some unintuitive outcomes.
That’s all well and good, you say, but the original question we were trying to answer was about what filesystem semantics make sense, not which database transaction semantics make sense. So that begs the question; do these anomalies transfer to the filesystem use case?
Unix filesystems vs transactions
Now let me reveal one detail I’ve been hiding from you. Remember the little transaction sequence I shared with you earlier mimicking file deletion being concurrent with other operations? At the time, I said “you can get the following output.” Turns out, you may not get the same output! For Postgres, that sequence of operations succeeds under Repeatable Read or weaker isolation levels, but if I try running it under Serializable, I get:
T1: read "k" -> "x"
T1: ERROR 40001: could not serialize access due to read/write dependencies among transactions
T3: read "k" -> (not found)
# T1's operations cannot continue as T1 was rolled back due to error
T1: SKIP read "k"
T1: SKIP commitThat’s interesting. So the most intuitive transaction isolation level
in a database, which is Serializable,
doesn’t allow a sequence of operations that are allowed by a Unix filesystem.To be more specific, Unix filesystem semantics are arguably closer to Read Uncommitted/Read Committed (and not even Repeatable Read), because an open file handle can observe changes made by other processes. Since there is no native notion of a COMMIT, I think it doesn’t make much sense to break this down further.
So perhaps there is something unintuitive about Unix filesystem semantics.
For example, if you were writing temporary files one at a time,
and then reading them back up later, and someone deletes your files
in the middle, your later open calls would fail
even though you thought your successful accesses earlier implied
that the files exist. So the “error” has been delayed to a later
stage when you try to re-read the files, instead of you hitting an error
on your file accesses immediately after deletion.
OK, that’s one potential example, but maybe you haven’t really run into this kind of situation before. Let’s try to think a bit more generally. Recall the two examples given by Kleppmann:
- The one related to Read Skew involved a long-running backup operation.
- The one related to Write Skew involved a sequence of doing some reads, making a decision, and writing some output based on that.
Can you think of some examples where similar patterns of reads and writes come up in the context of files? Here are some examples I came up with:
- IDEs and build systems esp. with incremental builds and caching (and similar systems such as hot reloading).
- Concurrent git operations on a repository.
- Indexing for search (e.g. Spotlight on macOS) running concurrently in the background.
- Software installation and uninstallation.
- Disk backups.
So these patterns of reads and writes are not specific to databases, but arise naturally in the context of filesystems as well.
However, Unix filesystems do not natively support transactions.
In SQL terms, there are no well-defined notions of BEGIN or COMMIT or ROLLBACK
in the context of filesystem operations;
even the mapping I made earlier was done in a hand-wavy fashion.
This means that applications which need to deal with concurrent modifications are entirely on their own with regards to how they want to handle such situations.
When you are emptying the Trash on macOS, and simultaneously trying to move things to Trash, because there is no notion of transactions, the deletion operation has no reliable way of having a consistent snapshot of what files you meant to delete. If files are being copied in, or being modified, if the file manager were to assume that you meant to delete everything, it could lead to accidental data loss. On the other hand, if it were overly conservative, it may end up retaining a lot of files (and hence, disk space), which is perhaps the opposite of what you intended when you performed the ‘Empty Trash’ action.
Or consider git. Have you ever hit the situation where you’ve hit Ctrl-C
in the middle of a git operation, or have had multiple git operations
running in parallel, and you’ve got your repository into a weird state?
Maybe you’ve had to delete a lock file manually.
Git uses file locking in conjunction with custom file formats to store data,
instead of an actual database.Not all version control systems are like this. For example, Fossil uses SQLite for storage.
This means that it’s very much possible to end up in such weird intermediate states
when things go wrong.
Is it possible to work around these limitations to varying extents in userspace? Maybe, it depends on the situation and constraints.
For example, in the context of build systems, if you have a single build server per project (like Bazel), then the build server can take care of safely running things in parallel without different parts of the build trampling on each others’ outputs. In version control land, you can try to do most of the things in memory first, to reduce the window of inconsistencies, like how git-branchless does rebases in-memory.
OK, so does this mean that Unix filesystem deletion semantics are worse than those of Windows? No, that’s not what I’m saying. To answer that, we have to clearly articulate a theory that can answer this (and many other questions), like how Powell spelled out the distinction about when to use positional vs keyword arguments.
A deeper theory of concurrent file modification
Recall that the idea of handling concurrent modifications is a more general one than that of handling concurrent file modifications.
Here is a partial theory of concurrent modifications:
- If you can avoid them, you should, because concurrent modifications can lead to unintuitive results (e.g. readers/writers may not be aware of presence of other concurrent writers).
- Locks can work well in some situations.
- Mandatory locks force cooperation. If cooperation is not possible,
mandatory locks can lead to starvation in absence of forced cancellation
(e.g. timeout errors, termination).
- Forced termination introduces issues of its own around ‘safe points’; see complexities on signal safety on POSIX systems, async exception safety in Haskell etc.
- Advisory locks (e.g.
flockon Linux) may be sufficient in cooperative settings. - Mandatory locks offer stronger safety guarantees than advisory locks.
- Using locks introduces the possibility of deadlocks.
- Mandatory locks force cooperation. If cooperation is not possible,
mandatory locks can lead to starvation in absence of forced cancellation
(e.g. timeout errors, termination).
- Transactions are a well-established mechanism for supporting complex patterns
of concurrent modifications, including modifications of objects in bulk.
- Transactions offer a more understandable model for concurrent modification, at the cost of more run-time overhead.
- Transactions allow accessors to pretend as-if they have exclusive access to the underlying data. The fidelity of this illusion depends on the isolation level.
- Stronger isolation levels of transactions are more intuitive than weaker
isolation levels, because they eliminate certain kinds of anomalies.
- This means that certain sequences of operations may be disallowed at stronger isolation levels, surfacing serialization errors.
- Generally stronger isolation levels impose more run-time overhead for conflict detection.
This is deliberately incomplete – for example, I didn’t cover message passing at all – but it should suffice for the sake of the discussion we want to have here.
So can we explain the Windows vs Unix difference in these terms?
In the absence of other concurrent accesses, users don’t observe a distinction between the two when deleting files.
Windows having semantics similar to RW locks leads to the expected issues of potential starvation/blocking if there are active accesses when we want to delete a file.
- Windows could potentially return errors to concurrent readers/writers on the next/running I/O operation. This could potentially introduce more complexity in error handling code (Ousterhout notes this in the book).
- Windows could potentially offer you the ability to terminate contending accesses, but that would introduce risks of its own. For example, the application having an open handle to the file may be in the middle of doing some work where it doesn’t expect to be terminated, so it may not be able to handle the situation on restart. Maybe even the source code for the application is no longer available.
The Unix semantics provide individual processes with their own isolated “bubbles”, to a certain extent, similar to transactions.
- However, these “bubbles” are actually quite permeable, unlike transactions.
- Because the Unix semantics are closer to weaker isolation levels, the semantics of concurrent operations can be counter-intuitive to people.
- They are actually not sufficient for all classes of applications because:
- Not all processes may cooperate.
- There is no native support for bulk modifications.
So while Unix’s semantics gracefully handle the lack of cooperation
amongst processes in some situations, they do not provide sufficient
mechanisms for dealing with concurrent modifications generally.
Moreover, APIs such as flock on Linux add more complexity to the mix.
This means that applications which (1) use filesystem APIs (due to self-imposed reasons or because of interoperability requirements with other software) and (2) have high reliability requirements (self-imposed or imposed by users) need to make careful trade-offs on a case-by-case basis.
However, that’s not the end of the story.
Is our theory actually true?
Recall Powell’s description of what a good theory needs to be able to do:
If the theoretical framework we’re coming up with is actually true, it actually has some substance, then it allows us to predict things, it allows us to extrapolate, and it allows us to distinguish between two things that might look the same.
Based on the theory I outlined, we would make the following predictions:Notably, we would not predict there being a portable way of performing transactions at the filesystem-userspace API boundary, because standardization requires deep collaboration, and many existing filesystems would not be able to support such an API without extensive changes.
- We should expect the OS to guide applications to rely more on application-specific storage by default, instead of on shared storage.
- We should expect filesystems to become more database-like in their implementation, perhaps with native support for transactions.
- We should expect databases to trend towards having stronger isolation levels by default over time, as hardware performance improvements and the development of new techniques brings the overhead of stronger isolation levels down to acceptable levels, or as the database imposes more constraints on the application.
Are these actually true in practice?
I think there are some signs in support of these points:
- Mobile operating systems have tended towards requiring more permissions from applications when accessing global directories.
- Modern file systems such as ZFS and Fuchsia’s FxFS use transactions internally, by default.
- In the case of databases:
- Google Cloud Spanner provides a guarantee called ‘External Consistency’ which is stronger than Serializability (docs).
- AWS Aurora DSQL, built on top of Postgres, offers Repeatable Read as the default and only transaction isolation level, which is stronger than Postgres’s default of Read Committed.
- TigerBeetle, a database specialized for financial transactions,
ensures Strict SerializabilityEdited on July 22, 2025. Thanks to Alex Kladov and Chaitanya Bhandari for pointing out the mistake. The older version of the blog post stated that TigerBeetle only guaranteed Serializability.
for transactions, which as the name suggests, is a stronger guarantee than Serializability. - Convex, a reactive database, defaults to Serializable transactions, and can automatically retry changes because of determinism guarantees. (docs)
That said, it’s possible that I’m wrong here. I’m not 100% sure, because I don’t work on operating systems, filesystems or databases – it’s possible that I’m just picking these examples because of confirmation bias. If you think there are major errors in the above, please send me an email (contact info on home page).
Closing thoughts
The analysis above is about 3000 words.
In contrast, the section in Ousterhout’s book on the file deletion example is less than 400 words. In a sense, this is understandable, because I believe the best lens to view A Philosophy of Software Design is really as a course textbook for Ousterhout’s course on software design at Stanford, for undergraduates.
It is also understandable as to why Unix filesystems have not historically supported transactions. The scale of hardware, usage, and concurrency at the time at which Unix was invented were totally different than what we have today in 2025. Moreover, if I’m not mistaken, some of the techniques for faster implementation of stronger isolation levels were invented around or after 2010.
It’s understandable why things are the way they are, but I want things to be different. In particular, I hope that the next time you read or hear someone articulating a theory of how to design programs, or even just a particular kind of program, you ask yourself:
- Does this match up with the examples I’ve seen?
- Does this allow me to extrapolate, to predict things?
- Does this make it clear where the boundaries and limitations are?