I recently fixed a bug at work.
When I realized what the fix was,
I let out an audible sigh of disappointment,
because it felt like a “stupid” bug.
I was a little bit angry at the different people
whose code had contributed to the bug.
My immediate thought was one of indignation
(“ugh, this could’ve been prevented by construction if they’d used a newtype wrapper here!”)
followed by some self-righteousness
(“well, the code I wrote in this other codebase is not going to have this kind of issue because I used more newtypes there”) and some speculation in my own favor
(“some of the code would not have passed code review had I been the code reviewer”).
As I paused to go drink some water,
while I was standing at the sink,
another thought crossed my mind,
“Uh, what did I just do here?
I somehow managed to convince myself that I’m better than the programmers whose code was involved.
But I know that the people who were involved in writing the code are not stupid.
It’s not like the bug was added intentionally…
So have I actually understood how the bug came about?”
After that, I spent some time reflecting on the bug,
in a calmer state of mind.
I want to share those reflections with you.
Background context
A brief history of the codebase
I work at Sourcegraph,
and the team I’m on is responsible for developing
and maintaining language-specific indexers for supporting
compiler-accurate code navigation actions – such as Go to definition
and Find references – inside Sourcegraph.
The indexers typically use a compiler or a type checker as a library.
If that’s not possible, we fork the compiler/type checker codebase,
and add indexing functionality there. For reference, adding indexing
functionality to an existing codebase typically takes ~3K SLOC,
whereas an industrial strength type checker (not to mention a full compiler)
is typically between 30K~100K SLOC.
Python is a popular language, so several customers were interested
in precise code navigation support for it in Sourcegraph.
Several years back, there were two major type checkers for Python -
MyPy (implemented in Python) and Pyright (implemented in TypeScript).
We noticed that:
Pyright had better performance (about 2x~3x the speed of MyPy at the time, IIRC)
Pyright had orders of magnitude fewer open issues
compared to MyPy.As of Aug 2025, MyPy has had ~13K commits and has 2.6K open issues. In contrast, Pyright has had ~8.3K commits and has 93 open issues. I believe the ratio of open bugs was even more pronounced in Pyright’s favor 3 years back.
However, Pyright was not usable as a library. So we decided to fork it
and build an indexer scip-pythonThe ‘scip’ is pronounced as ‘skip’.
on top of it.
The forking decision was made about 3 years back.
Due to various factors,
the scope of the code our team owns has grown,
while the team size has shrunk. The person who did the initial
development of scip-python is no longer at the company.
We have limited maintenance capacity for the indexers themselves.
We attempt to fix bugs – particularly the ones
prospects and customers run into – as capacity permits.
How scip-python is tested
Our indexers generally use snapshot testing
(aka golden testing),
as compilers and similar tools are very amenable to this kind of testing.
For example, part of a snapshot may have something like:
class InitClass:
# ^^^^^^^^^ definition `src.foo.bar`/InitClass#
If there are mentions of InitClass elsewhere which refer to the same
semantic entity, they’ll have a reference marker with the same symbol
`src.foo.bar`/InitClass#.This output is slightly simplified.
This makes it easy to understand the behavior of code navigation
without coupling the indexer to the backend which actually implements
code navigation support.
The situation
Recently, we got a bug report of a crash a customer encountered
when attempting to run scip-python on their (private) codebase.
The issue did not come with a minimal reproducer, so it was up to
us to try to come up with one.
First, I just attempted to run the tests on my work Macbook.
When attempting to run the tests,
exactly one snapshot test was failing with mismatch in the output.
I’m showing a subset of the output, the actual diff was similar
but for about 35 lines total.
What is happening here is that at the reference range,
the symbol is missing the module prefix `src.foo.bar`.
This means that code navigation will not work from the reference site
to the definition site we saw earlier,
because the symbols need to match exactly.
At Sourcegraph, employees generally use Macbooks.
The CI pipeline for scip-python was using Ubuntu and it was passing.
There was no CI pipeline for macOS.
When I saw this failure, I vaguely remembered having hit this bug earlier,
and not having been able to figure out a fix within a day or two of debugging.
I thought that before fixing the crash the customer hit, it’d be good to
make sure that all tests were passing on macOS for ease of local development
(instead of adding a hack to skip a test on macOS), and set up CI for macOS.
I gave myself a time budget of 3-4 days.
In the past, I had not done much work on scip-python’s codebase.
So I had little context. The little context that I had,
I’d already lost by the time of starting debugging this issue,
because I hadn’t worked on the codebase recently.
What I did
I used an AI coding assistant to onboard myself,
to help with running commands,
to add print debugging statements in lots of places,
and to compare the logs on macOS vs Linux to identify the places
of divergence.
While doing other work in parallel, I was about able to figure
out a one line fix in a couple of days.
The fix involved normalizing the paths being added to a Program object
(essentially a kind of god object/global state/context)
using an existing helper function.
This helper function would lowercase the paths
on case-insensitive file systems (such as macOS’s APFS)
and leave them as-is on case-sensitive file systems
(such as ext4 on Linux).
This was a one line fix as the path normalization function
took an input path of type string and returned a normalized path of type string.
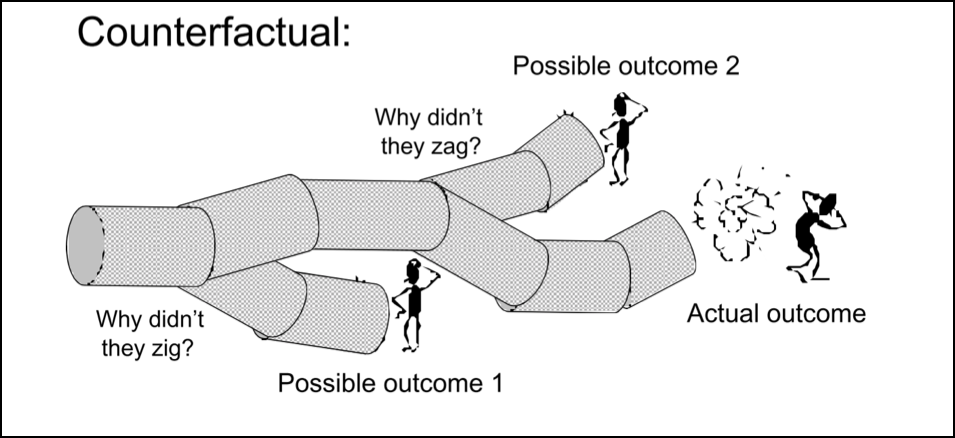
Aside: Counterfactual reasoning
Per Wikipedia:
Counterfactual thinking is a concept in psychology that involves the human tendency to create possible alternatives to life events that have already occurred; something that is contrary to what actually happened. Counterfactual thinking is, as it states: “counter to the facts”. These thoughts consist of the “What if?” and the “If only…” that occur when thinking of how things could have turned out differently. Counterfactual thoughts include things that – in the present – could not have happened because they are dependent on events that did not occur in the past
Counterfactual reasoning is dangerous when attempting to understand why things happened the way they happened, and why people made the decisions they made, because it assumes an omniscient God-like view of not only the past, but also of potential futures that were not taken. Sidney Dekker has an evocative image about this:
Counterfactual reasoning involves taking a view from “outside” the tunnel, with a full map, without necessarily understanding what people in the tunnel were experiencing.
In the rest of this blog post, I will highlight examples of counterfactual statements and counterfactual reasoning with the ⚠️ emoji.
Three potential analyses of the bug
OK, so now you know a bunch of background about the bug,
as well as the fix.
Let’s try looking at it in a few different ways.
A simple “cause”
An attempt at identifying the “root cause”
An attempt at identifying some contributing
factors to the bug
Analysis 1: What “caused” the bug?
This bug was “caused” by the code not (⚠️) correctly
normalizing the paths before adding them to the Program instance.
Analysis 2: ‘Five Whys’ and the “root cause”
Five Whys is a technique
purportedly used to identify the “root cause” of a problem
by repeatedly asking ‘Why?’ questions.
As the name suggests, the canonical number of ‘Why?’ questions is five,
but depending on who you ask, this number can be tweaked.
I believe it is somewhat popular,
in that I’ve met people who know about this,
but I’m not sure.
Let’s try it here.
Initial statement: The snapshot output was different on macOS vs Linux.
Why was it different?
A: On macOS, the code was setting a property moduleName to an empty value, leading to this bug. On Linux, the moduleName was set to a non-empty value.
Why was the module name set to empty on macOS?
A: On macOS, when the code ran, it used normalized paths from one code path, and non-normalized paths from another code path. These paths were used as hash map keys, leading to certain lookup operations returning undefined during import resolution. This was later propagated through as moduleName: ''.
Why was the code passing normalized paths in some cases and not others?
A: These code paths were written by different people.
The code where the paths were passed as-is was written by the person who forked Pyright
and was the original scip-python maintainer.
The lead (solo) maintainer of Pyright wrote the other code where the paths were first normalized.
The original scip-python maintainer perhaps did not have sufficient context (⚠️)
of the unstated but important (⚠️) pre-conditions of different APIs. ️
It’s hard to know for sure.
Why did the original scip-python maintainer not notice (⚠️) and fix the test failures on macOS?️
A: They were using a Linux machine for development. I believe that they got this machine before the company-wide Macbooks only policy was announced, or maybe they got an exception. The CI was Ubuntu only, so there was no environment where they would notice this, unless someone else was also running the tests locally.
Why was macOS not tested (⚠️) in CI if developers use Macbooks locally?️
A: I’m not sure, but if I were guessing, it’s probably because the person didn’t anticipate (⚠️) that an indexer for Python written in TypeScript would have major differences between OSes (unlike, say, an indexer for C++, potentially written in a compile-to-native language), so they must’ve thought that testing on Ubuntu would be sufficient.
Additionally, in production, the indexers generally run on Linux.
OK… So is the “root cause” of the bug the lack of anticipation when setting up CI?
Maybe you think that’s not a very good attempt at Five Whys.
Below, I’ve attempted to formulate some more questions – such as those people might ask in forum comments – and answer them faithfully.
Q: Why does the codebase use a string type for paths? (+ optionally some mention of boolean blindness, primitive obsession etc.). Some variations on this question might be:
(Statement): This bug could’ve been prevented by just using different types for different paths. (⚠️)
Why did the original maintainer not define dedicated types for non-normalized paths vs normalized paths? (⚠️)
A: I don’t know the full answer, but I suspect some contributing factors may have been:
The NodeJS platform APIs use string | Buffer | URL for path arguments.
Out of these, string is convenient for many operations.
Invariants in TypeScript can be captured using classes.
Values of class types have reference semantics when used as Map keys, making Map usage cumbersome (you would need a a separate conversion to a string for value-based equality).
Potential conversions for a dedicated Path type to and from string would require extra allocations,
potentially affecting performance for large codebases.
Q: Why was this bug/the lack of CI for macOS/something else not caught (⚠️) during code review?
A: The team was spread out working on indexers in many different languages, as well as working on other things. We did not have capacity for code review across work streams. Most of the indexers have been brought up and maintained by individuals.
Q: Why was the original scip-python maintainer not using (⚠️) a Macbook like everyone else? (+ optionally: (Statement) If they were using it (⚠️), then they would’ve figured out the bug earlier.)
A: I don’t know. I suspect it probably came down to the belief from the exec team that some people who’d
already set up a powerful Linux computer and were not used to Macbooks at all were likely
to be much more productive on their existing Linux machines, but that’s just a guess.
OK… So what is the “root cause” in light of the above?
Is the absence of composite value types (⚠️) in TypeScript the “root cause”?
Is the “poor” API decision of not having (⚠️) a dedicated type for normalized paths and using that pervasively the “root cause”?
Is the upper-level management decision to have a certain amount of staffing for the team the “root cause”?
Is the “root cause” the team manager’s decision to spread the team thin (⚠️) across a larger surface area?
Analysis 3: Contributing factors
Let’s try listing down the various factors which contributed to this bug.
For this list, I’ve taken care to avoid counterfactuals
(this was difficult!). The list is, by definition, incomplete.
APFS on macOS is case-insensitive: macOS’s APFS is likely case-insensitive by default
to avoid breaking backwards compatibility with HFS+ and ancestors
(related Apple StackExchange answer).
JS only supports reference semantics for composite types:
JavaScript historically has only had reference types
for composite values (e.g. a pair of numbers).
The Records and Tuples proposal
to add deeply immutable composite types was withdrawn.
There is a separate Composites proposal
which is currently under consideration.
TS compiles to JS: TypeScript compiles to JavaScript, as JavaScript has historically been
the only language supported by browsers.
This choice of compilation target prevents efficient implementation
of composite types with value semantics in TypeScript
as long as JavaScript doesn’t support them.
Pyright is written in TypeScript: I don’t know why this choice was made,
but my guess is that TypeScript was probably picked
to avoid a two-language codebase for Pylance,
which is Microsoft’s proprietary extension for Python code intelligence in VS Code,
built on top of Pyright.
VS Code uses Electron, which is built on web technologies,
so it’s unsurprising that VS Code extensions have
historically been written in JavaScript or TypeScript.
macOS w/ APFS is the default at Sourcegraph: Sourcegraph issues Macbooks for new
employees because they’re fairly powerful and well-liked.
Most Sourcegraph employees using Macbooks run macOS, with APFS as the file system,
because those are the defaults.
Additionally, I believe the device management software prevents usage of other
OSes natively (containers are fine).
scip-python is a fork of Pyright due to reasons I mentioned
in the Background Context section.
Bus factor of 1 on scip-python:
The original work on scip-python was done by one person due to limited team capacity
as well as desire to have precise code navigation support (and hence indexers)
for many different languages.
Resilient design of Pyright and scip-python:
Pyright as well as scip-python are generally written to be resilient to ill-formed
programs, including (but not limited to) programs with broken/unresolvable imports
(e.g. due to dependencies not being installed).
For scip-python in particular, we want the indexer to be able to index as much
of the code as possible, instead of bailing early at the first sign of something
going wrong.
These two requirements likely contributed to a coding style where it is less common
for code to bail on the sign of seeing something funky,
but to instead keep going.
Doc comment patterns in Pyright:
Pyright itself is largely maintained by a single, highly experienced person,
who has been working on it for a long time.
So for the maintainer, the existing comments in the codebase, particularly
function-level and field-level doc comments, may be sufficient.
Empty moduleName property:
There are certain code paths in Pyright internals which set a property called moduleName
to '' when receiving a file path which hasn’t been seen earlier.
(As can happen if you’re passing paths after normalizing through one code path,
and without normalizing through another code path.)
Based on my reading of the scip-python code, it seems like the code accessing
the moduleName property was written with the assumption that it would
never be empty.
You might be wondering: so what we do with this list now?
Shouldn’t we at least discard some points for simplicity?
For example, lots of applications run fine on macOS,
and lots of applications written in TypeScript don’t necessarily
have the same kinds of bugs.
To that, my response is, yes, we can discard points.
But our choice to discard individual points doesn’t mean
that these did not contribute.
If we consider the point about case-insensitivity of APFS,
a quick web search will reveal that case-insensitivity
on macOS (or Windows, for that matter) often bites programmers used to Linux.
For example, Case-insensitive filesystems considered harmful (to me)
talks about a build failure when using the Kotlin compiler
along with a specific code pattern,
that only triggers on case-insensitive file systems such as
on macOS and Windows.
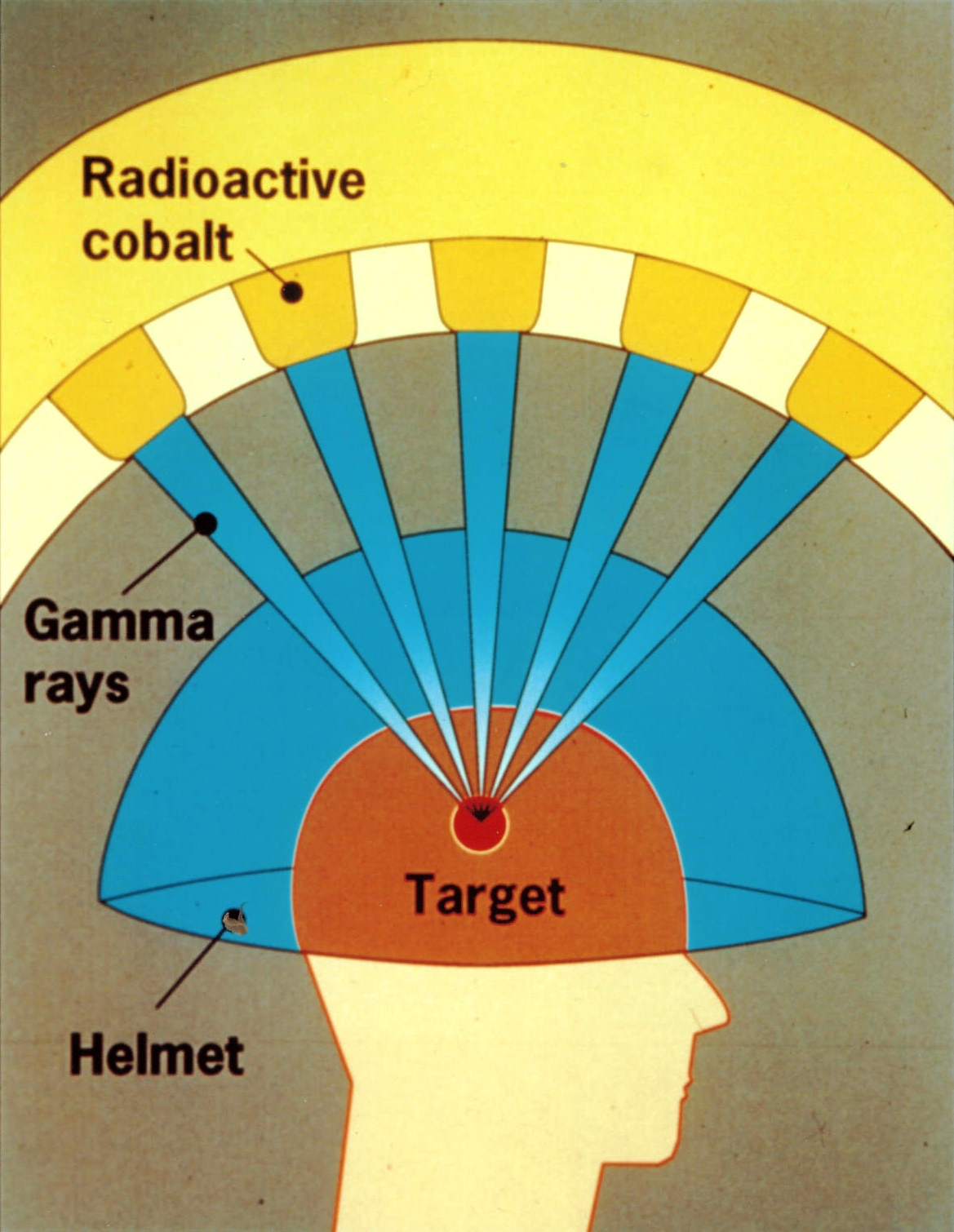
Gamma knife is a system that surgeons use for treating brain tumors by focusing multiple beams of gamma radiation on a small volume inside of the brain.
Illustration of a gamma knife, with multiple beams of radiation converging.
Each individual beam is of low enough intensity that it doesn’t affect brain tissue. It is only when multiple beams intersect at one point that the combined intensity of the radiation has an impact.
Every day inside of your system, there are things that are happening (or not happening(!)) that could potentially enable an incident. You can think of each of these as a low-level beam of gamma radiation going off in a random direction. Somebody pushes a change to production, zap! Somebody makes a configuration change with a typo, zap! Somebody goes on vacation, zap! There’s an on-call shift change, zap! A particular service hasn’t been deployed in weeks, zap!
Most of these zaps are harmless, they have no observable impact on the health of the overall system. Sometimes, though, many of these zaps will happen to go off at the same time and all point to the same location. When that happens, boom, you have an incident on your hands.
Alas, there’s no way to get rid of all of those little beams of radiation that go off. You can eliminate some of them, but in the process, you’ll invariably create new ones.
To this, I can imagine someone reasonably bringing up a few different objections:
The metaphor sounds interesting, but what I’ve said is not very actionable.
Is my point that we should just give up on trying to improve things,
such as using by alternate/“superior” coding patterns?
There is a big difference between the bug I described and
the kinds of incidents that Hochstein is talking about.
Let me cover the second point first.
Consider this one hypothetical gamma ray:This is meant as a creative example, not a reflection of day-to-day operations.
The CEO is going to be talking to a big prospect (Python shop) in an hour, and they are interested in precise code navigation for Python. This meeting was set up on short notice, so there was no heads up. The CEO indexed a popular Python codebase using his Macbook, but code navigation is not working correctly. The CEO needs urgent support.
So perhaps, the difference between a bug and an incident is not as big a difference
as it might seem at first glance?
Coming back the first question:
surely, we need some actionable takeaways from a bug analysis/retro, right?
Surely, I must agree that defining a dedicated type for normalized paths,
by virtue of being a more systemic fix, is the “best” solution, right?
Path handling scar tissue
At my first job at Apple,
the first slightly complex PR that I created against the Swift compiler
involved modifications to a so-called module trace file
emitted by the compiler for an Apple-internal build system.
One of the key bits of information recorded in this module trace are paths to
various files that are consulted by the compiler.
When creating this PR, I recall spending a fair bit of time trying
to understand the various cases of when certain paths would be relative
vs absolute, and if they were relative, then relative to what.
I distinctly remember asking my mentor at the time as to why we weren’t
using dedicated types for different kinds of paths.
I don’t remember the exact answer, but I think it was something
along the lines of nobody having suggested it earlier (at least,
based on what my mentor knew).
In retrospect, one big contributing factor is at least somewhat clearer.
The Swift compiler codebase is best viewed
as a close cousin of Clang;
multiple people who originally worked on Swiftc
previously worked on Clang.
There are a lot of similarities in coding patterns between the two.
And the Clang codebase does not distinguish various kinds of paths;
it generally uses the string type or a type representing a reference to a string.
In the end, I was still not super confident about the module trace PR
when I submitted it (and we still landed it),
and I ended up creating some follow-up PRs later
to make the logic more robust,
and to handle more cases.
That experience left a somewhat deep impression on me.
So when I joined Sourcegraph,
and I was working on a new indexer for C++,
I ended up defining several distinct types as follows:
An AbsolutePath type.
A RootPath which tracks an absolute path as well as
what kind of “root” we’re talking about:
The project root (usually the directory with .git).
The build root (e.g. a build/ directory with CMake,
often inside the project root, but not always).
An external root (e.g. for tracking paths related to third-party packages).
A RootRelativePath which defines paths relative to a certain RootPath.
This also tracks the root kind. So the method which combines
a RootRelativePath with a RootPath to create an AbsolutePath
can assert that the kinds match up, as a consistency check.
Is that the “best” way to do things? Probably not.
On looking at the code again, there are definitely parts
which are complex,
and it’d take me some time to make sense of them.
If building a theory of a program is like climbing,
then the finer-grained types feel like additional ledges
and footholds I can use,
instead of having to face a scarier, sheer wall.
I chose my current handle on various sites (typesanitizer)
in part because I held and continue to hold the belief that
most existing programs
which need to be maintained over several years or decades,
particularly with a varying set of maintainers,
would probably benefit from defining more distinct types
to capture different sets of invariants.
Coming back to the question I posed earlier:
Surely, I must agree that defining a dedicated type for normalized paths,
by being a more systemic fix, is the “best” solution, right?
In the situation where it makes business sense
for our team to spend more time on indexer maintenance, maybe yes.
In the current situation, the “best” solution is probably to do nothing.
Why? Because time is the biggest constraint.
Changing the code inside Pyright internals itself would potentially
take a large amount of upfront investment, and would make syncing
the fork with upstream harder (it’s already quite out-of-date).
Adding a wrapper type for Program in the code specific to scip-python
would likely require some invasive changes.
It would also add more indirection, potentially making code harder
to understand (i.e. a new zap!).
The places where scip-python’s own code interacts with paths is relatively
limited at the moment, so chances of the same kind of bug
coming up in the future is relatively limited, especially as scip-python
is not under active development.
If there is a bit of time, perhaps we can tweak the code paths which access
the moduleName field in scip-python to handle the empty case,
and just skip emitting a definition or reference.
We could potentially log a warning message for the user to file a bug,
and potentially include some debugging information in the warning,
but I’m not sure how easy it would be to reproduce the issue
without access to the code itself.
Some observations and beliefs
Coming back to the titular question:
How can we learn from bugs?
This question is well-intentioned, but unfortunately, it omits a key detail:
specifically, what learning are we talking about here? Do we mean:
“How can we learn (how to prevent the same bug in the future) from (old/existing) bugs?”
“How can we learn (how to prevent the same kind of bug in the future) from (old/existing) bugs?”
“How can we learn (how to write bug-free programs) from (old/existing) bugs?
“How can we learn (how to write successful (for some definition of ‘successful’) programs) from (old/existing) bugs?
“How can we learn (why the bugs came about) from (old/existing) bugs?”
Or maybe we mean something else.
Notice how all of these questions bake certain assumptions into them. For example,
“How can we learn (why the bugs came about) from (old/existing) bugs?”
is potentially silently accompanied by the assumption that future bugs are likely to resemble past bugs.
Depending on context, these assumptions may or may not be true.
For example, if your project heavily uses property-based testing
(or its more supercharged version deterministic simulation testing),
it’s possible that bugs at later times, more often than not, do not resemble
bugs in the past.
In any case, given the large variety of programs that people write,
the large variety of contexts programmers operate in,
and the large variety in bugs that programs have,
I do not feel confident enough
to actually provide an answer to the titular question.
That said, here are my observations and beliefs:
Taking bugs seriously can be a double-edged sword.
Avoiding counterfactuals is hard,
but probably a net positive when analyzing bugs.
Paying attention to contexts which ideas originate in,
as well as to the difference in contexts
when attempting to apply said ideas,
is generally useful.
‘Depth’ is a property of analyses of bugs;
it’s not a property of bugs themselves.
Let’s walk through each of these.
The two sides of taking bugs seriously
When I say “taking bugs seriously”, I mean that as shorthand for
operating with a core belief that it is possible to eliminate
certain (kinds of) bugs to a significant extent from programs that
one is yet to write in the future by doing something in the present,
and that striving to reduce bugs is worth the effort.
On one hand, it seems highly likely that if you have this kind of mindset,
then you will probably try to find new techniques, experiment with them,
and reduce or eliminate certain (kinds of) bugs from the programs you write.
Depending on the context, this may be helpful for you.
On the other hand, I think there is a mental cost
when actually encountering certain bugs.
For example, maybe you thought you eliminated the possibility
of a certain kind of bug, but actually, someone (maybe yourself!)
managed to write code a certain way to trigger it again.
Or maybe you’re working on a codebase written by other people,
and you run into bugs which you know can be avoided
by writing code a certain way.
And sometimes, giving up / not doing anything is the best option,
and that can be frustrating.
Earlier, when I wrote the words that doing nothing was probably the “best”
solution in the current situation for the path handling in scip-python,
there was an agitated voice in my brain going
“do you really believe this??” as well as a more sarcastic voice going
“so you’re saying we must imagine Sisphyus happy?”
As much as I’d like to be equanimous when encountering bugs or debugging,
sometimes, feelings do get in the way.
Avoiding counterfactuals is worth the effort
Counterfactuals come up very naturally in thinking.
While you were reading the earlier sections,
particularly the “root cause” analysis,
you might’ve been able to relate the example
to some situations you’ve encountered at work.
You’ve probably seen people frame bugs as
“If X were the case, this bug wouldn’t have happened.”
– it probably happens all the time.
A few months back, I wrote an ~8K word incident report at work.
As part of the process, I interviewed the people who were
involved in the incident, some live, and some async.
By far the hardest thing about this process was avoiding
counterfactual questions, both in live interviews
as well as during async interviews.
The problem with counterfactuals is that they generally assume an omniscient view
of the history of the situation. But well-meaning people generally make the decisions
they make because those decisions make sense to them,
given their knowledge, skills and information about the situation they are in,
at the time they made the decision.
So to understand why things happened the way they happened, it is generally
more useful to frame questions such as:
What did the people involved know at the time?
What were the constraints they were operating under?
rather than, “why didn’t they do X?”
The recent discussion on an OpenZFS bug is a good example of this.
Some commentors were much more focused on how the bug
could’ve been avoided if XYZ were true
(where XYZ is known to not have been true),
rather than how the bug came about to be,
why the codebase uses the naming conventions
that it does, etc.
Paying attention to contexts
If you’re a programmer, your day-to-day work involves taking things from
one context and using them in another context.
A new username typed on a website becomes part of a new row in a database.
A function name written in a text file becomes a debug symbol in an object file.
A Set type defined in the standard library becomes a way to model
a business constraint of no duplicates.
So it’s entirely unsurprising when we attempt to take ideas from one context
and try to apply them in other contexts – that’s literally part of the job.
However, when we decontextualize bugs, or approaches for avoiding bugs,
I believe we reduce the probability of the conversation having a constructive outcome.
Approaches for avoiding certain kinds of bugs that work in some contexts
may not be workable in other contexts because of business constraints,
limitations in the specific technologies, human factors such as inertia,
and so on. So it’s worthwhile to pay closer attention to context
when having discussions on particularly complex topics, such as bug prevention.
Depth is a property of analyses of bugs; not of bugs themselves
Generally, I’ve seen the time spent on discussing or analyzing a bug
is correlated with the impact it had, either internally,
or on a customer. For example, incidents receive more eyeballs
than bugs which didn’t turn into incidents, and bugs hit by
customers are discussed more compared to bugs which are not.
This might lead one to think (or maybe it is a reflection of the implicit assumption)
that bugs which had more impact are “deeper”,
i.e., they warrant a deeper analysis because there is likely more to learn from them,
and spending effort deeply analyzing on high-impact bugs
will have higher expected utility
(as compared to deeply analyzing low-impact bugs**.
I suspect that this implicit assumption is false,
but I do not have compelling evidence either way.
At some point, I’d like to run an experiment of
deeply analyzing low-impact bugs,
as well as deeply analyzing high-impact bugs,
and comparing the impact of the analyses.
Measuring impact is hard though; that’s just
one complication of many potential complications,
when trying to test this in a manner
where the results are usable for other people.
Aside: Depth ≠ fitness-for-purpose
Perhaps there’s one additional bit that’s worth clarifying:
I’m not implying that deeper analyses are necessarily more fit-for-purpose.
Whether an analysis is fit-for-purpose depends on the purpose
it is being used for, and the constraints you have when you’re
doing the analysis.
For example, if you’re working in an environment where there’s
pressure on you to provide concrete action items to prevent bugs,
and yet business constraints mean that you only have limited time
to actually follow up on the said action items,
then a “root cause” analysis process would likely be more fit-for-purpose
than the kind of contributing factors analysis I presented earlier.
Closing thoughts
I don’t know how we should learn from bugs.
I think there are at least some situations in which we cannot do anything
about certain kinds of bugs until the situation/context changes,
and it is important to come to terms with that for the sake of one’s mental health,
instead of being indignant in the face of bugs.
Depending on the person, accepting this can be hard.
At the same time, there may be situations in which we can improve things,
such as subsystems where one has greater influence, or greenfield projects,
and it makes sense to focus one’s energy on trying out
new bug prevention techniques in those contexts.
When we’re discussing bugs with others,
as well as when we’re debugging by ourselves,
I think, on average,
we could probably do with extending more grace,
and starting with questions instead of solutions.
P.S.
If you’re reading this via a forum,
and you’ve spent a fair bit of time thinking about the
meta question ‘How should we learn from bugs?’,
or maybe even just trying different things
(such as running different kinds of retro processes),
I’d love to hear from you in a forum comment
or via email (contact info on homepage).